- n.
WordNet
- capacity or power to produce a desired effect; "concern about the safety and efficacy of the vaccine" (同)efficaciousness
- works well as a means or remedy; "an effective reprimand"; "a lotion that is effective in cases of prickly heat"
- producing or capable of producing an intended result or having a striking effect; "an air-cooled motor was more effective than a witchs broomstick for rapid long-distance transportation"-LewisMumford; "effective teaching methods"; "effective steps toward peace"; "made an effective entrance"; "his complaint proved to be effectual in bringing action"; "an efficacious law" (同)effectual, efficacious
- able to accomplish a purpose; functioning effectively; "people who will do nothing unless they get something out of it for themselves are often highly effective persons..."-G.B.Shaw; "effective personnel"; "an efficient secretary"; "the efficient cause of the revolution" (同)efficient
- exerting force or influence; "the law is effective immediately"; "a warranty good for two years"; "the law is already in effect (or in force)" (同)good, in effect, in force
- existing in fact; not theoretical; real; "a decline in the effective demand"; "confused increased equipment and expenditure with the quantity of effective work done"
- ready for service; "the fort was held by about 100 effective soldiers"
- the quality of having legal force or effectiveness (同)validness
- power to be effective; the quality of being able to bring about an effect (同)effectivity, effectualness, effectuality
PrepTutorEJDIC
- 利用できること,有用性,利用価値
- (…に対する,における)効きめ,効力《+『against』(『in』)+『名』》
- 『効果的な』,効きめのある / (法律などが)『有効な』,実施されている / 印象深い,感銘的な / 実際に役立つ,実動の
- (理論・理由などの)『妥当性』,正当性《+of+名》 / (契約などの)有効性,合法性《+of+名》
Wikipedia preview
出典(authority):フリー百科事典『ウィキペディア(Wikipedia)』「2015/11/30 18:12:21」(JST)
wiki en

![A(t)=\Pr[X(t)=1]=E[X(t)].](http://upload.wikimedia.org/math/9/e/b/9eb5df8d63662f715622da69b5ed9f71.png)

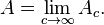

UpToDate Contents
全文を閲覧するには購読必要です。 To read the full text you will need to subscribe.
- 1. 脳炎または髄膜炎患者における単純ヘルペスウイルスの診断のためのPCR検査 pcr testing for the diagnosis of herpes simplex virus in patients with encephalitis or meningitis
- 2. 甲状腺ホルモンの作用 thyroid hormone action
- 3. β‐サラセミアメジャーにおける造血細胞移植の有効性 efficacy of hematopoietic cell transplantation in beta thalassemia major
- 4. 錠剤を嚥下できないHIV感染成人患者の治療:液剤、チュアブル、および砕くことができる剤形の薬剤 treatment of hiv infected adults who have trouble swallowing pills liquid chewable and crushable formulations
- 5. サンゴヘビによる咬傷の評価およびマネージメント evaluation and management of coral snakebites
English Journal
- Do Differential Response Rates to Patient Surveys Between Organizations Lead to Unfair Performance Comparisons?: Evidence From the English Cancer Patient Experience Survey.
- Saunders CL1, Elliott MN, Lyratzopoulos G, Abel GA.
- Medical care.Med Care.2016 Nov 24. [Epub ahead of print]
- BACKGROUND: Patient surveys typically have variable response rates between organizations, leading to concerns that such differences may affect the validity of performance comparisons.OBJECTIVE: To explore the size and likely sources of associations between hospital-level survey response rates and pa
- PMID 26595223
- Differential detection of a surrogate biological threat agent (Bacillus globigii) with a portable surface plasmon resonance biosensor.
- Adducci BA1, Gruszewski HA1, Khatibi PA1, Schmale DG 3rd2.
- Biosensors & bioelectronics.Biosens Bioelectron.2016 Apr 15;78:160-6. doi: 10.1016/j.bios.2015.11.032. Epub 2015 Nov 14.
- New methods and technology are needed to quickly and accurately detect potential biological warfare agents, such as Bacillus anthracis, causal agent of anthrax in humans and animals. Here, we report the detection of a simulant of B. anthracis (B. globigii) alone and in a mixture with a different spe
- PMID 26606307
- A high-throughput liquid bead array-based screening technology for Bt presence in GMO manipulation.
- Fu W1, Wang H1, Wang C1, Mei L1, Lin X1, Han X2, Zhu S3.
- Biosensors & bioelectronics.Biosens Bioelectron.2016 Mar 15;77:702-8. doi: 10.1016/j.bios.2015.10.043. Epub 2015 Oct 23.
- The number of species and planting areas of genetically modified organisms (GMOs) has been rapidly developed during the past ten years. For the purpose of GMO inspection, quarantine and manipulation, we have now devised a high-throughput Bt-based GMOs screening method based on the liquid bead array.
- PMID 26499065
Japanese Journal
- Thick-target yields of radioactive targets deduced from inverse kinematics
- Aikawa M.,Ebata S.,Imai S.
- Nuclear Instruments and Methods in Physics Research Section B: Beam Interactions with Materials and Atoms 353, 1-3, 2015-06-15
- … We apply the method to the natCu(12C,X)24Na reaction to confirm availability. …
- NAID 120005602532
- パブリッククラウドにおけるL2TPv3を用いたサーバ高可用性の評価
- 松本 直人
- 情報処理学会研究報告. IOT, [インターネットと運用技術] 2015-IOT-29(33), 1-3, 2015-05-14
- インターネットを介して計算機資源を利用するパブリッククラウドは日々拡大を続けている.しかしパブリッククラウドの多くはトラフィック制限により IPUnicast のみクラウドネットワーク上で利用可能であり,IPMulticast を用いた VRRP など高可用性を実現するプロトコルを使うことができない.本稿では,パブリッククラウド上の仮想マシンにおいて L2TPv3 プロトコルを有効とし,OSPFv …
- NAID 110009900818
- パブリッククラウドにおけるL2TPv3を用いたサーバ高可用性の評価
- 松本 直人
- 情報処理学会研究報告. CSEC, [コンピュータセキュリティ] 2015-CSEC-69(33), 1-3, 2015-05-14
- インターネットを介して計算機資源を利用するパブリッククラウドは日々拡大を続けている.しかしパブリッククラウドの多くはトラフィック制限により IPUnicast のみクラウドネットワーク上で利用可能であり,IPMulticast を用いた VRRP など高可用性を実現するプロトコルを使うことができない.本稿では,パブリッククラウド上の仮想マシンにおいて L2TPv3 プロトコルを有効とし,OSPFv …
- NAID 110009900784
Related Links
- availability 【名】 利用[使用]できること、入手[購入・利用・使用]の可能... - アルクがお届けする進化するオンライン英和・和英辞書データベース。一般的な単語や連語から、イディオム、専門用語、スラングまで幅広く収録。
- For drug users of most levels, she noted, “Cost, effectiveness, and availability are far more important than the legality.” How to Buy 'Pot' On Amazon Kia Makarechi March 26, 2010 That can create an illusory sense of availability ...
Related Pictures






★リンクテーブル★
| リンク元 | 「effective」「validity」「役立つこと」「usefulness」「effectiveness」 |
| 拡張検索 | 「unavailability」 |
「effective」
- adj.
- 効率的な、有効な、効果的な、効果のある、有効性の
- 関
- active、availability、effectively、effectiveness、efficacious、efficacy、efficient、efficiently、forceful、valid、validity
「validity」
- n.
- 関
- adequacy、appropriateness、availability、effective、effectiveness、efficacy、pertinence、reliability、usefulness、valid
「役立つこと」
「usefulness」
- n.
「effectiveness」
- n.