WordNet
- set up or distributed in a deliberately random way (同)randomised
- lacking any definite plan or order or purpose; governed by or depending on chance; "a random choice"; "bombs fell at random"; "random movements"
- (statistics) the selection of a suitable sample for study
- measurement at regular intervals of the amplitude of a varying waveform (in order to convert it to digital form)
- the basic unit of money in South Africa; equal to 100 cents
PrepTutorEJDIC
- 『手当たりしだいの』,任意の;行き当たりばったりの
- ラント(南アフリカ共和国の通貨の単位)
Wikipedia preview
出典(authority):フリー百科事典『ウィキペディア(Wikipedia)』「2015/11/30 15:56:47」(JST)
wiki en
![\begin{align}
P
&= 1 - \frac{N-1}{N} \cdot \frac{N-2}{N - 1} \cdot \cdots \cdot \frac{N-n}{N - (n - 1)} \\[8pt]
&\stackrel{\text{Canceling:}}{=} 1 - \frac{N - n}N \\[8pt]
&= \frac nN \\[8pt]
&= \frac{100}{1000} \\[8pt]
&= 10\%
\end{align}](http://upload.wikimedia.org/math/5/5/4/5546fbfcb9a64a7cacf999b6953a9ec2.png)
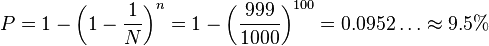
UpToDate Contents
全文を閲覧するには購読必要です。 To read the full text you will need to subscribe.
- 1. 胎児の採血 fetal blood sampling
- 2. 絨毛膜サンプリング検査:リスク、合併症、および手技 chorionic villus sampling
- 3. 証拠、p値、および仮説検定 proof p values and hypothesis testing
- 4. システマティックレビューおよびメタアナリシス systematic review and meta analysis
- 5. 卵巣癌、卵管癌、および腹膜癌:病期分類および初期外科的マネージメント cancer of the ovary fallopian tube and peritoneum staging and initial surgical management
English Journal
- The study of KBP of road construction workers of highway AIDS prevention project before and after intervention.
- Liu D, Dong SP, Gao GM, Fan MY, Zhang ZJ, Fang PQ.SourceSchool of Medicine and Health Management, Tongji Medical College, Huazhong University of Science and Technology, Wuhan 430030, Hubei, China.
- Asian Pacific journal of tropical medicine.Asian Pac J Trop Med.2013 Oct;6(10):817-22. doi: 10.1016/S1995-7645(13)60144-3.
- OBJECTIVE: To get scientific basis for further health education through the research of the road construction workers' KBP before and after the interventions of highway AIDS prevention project.METHODS: Multi-stage random sampling method was employeed to select workers of 8 sites from 14 sites along
- PMID 23870472
- An intrinsic algorithm for parallel poisson disk sampling on arbitrary surfaces.
- Ying X, Xin SQ, Sun Q, He Y.SourceNanyang Technological University, Singapore.
- IEEE transactions on visualization and computer graphics.IEEE Trans Vis Comput Graph.2013 Sep;19(9):1425-37. doi: 10.1109/TVCG.2013.63.
- Poisson disk sampling has excellent spatial and spectral properties, and plays an important role in a variety of visual computing. Although many promising algorithms have been proposed for multidimensional sampling in euclidean space, very few studies have been reported with regard to the problem of
- PMID 23846089
- The effectiveness of a health education intervention on self-care of traumatic wounds.
- Chen YC, Wang YC, Chen WK, Smith M, Huang HM, Huang LC.SourceDepartment of Emergency Medicine, China Medical University Hospital, Taichung, Taiwan.
- Journal of clinical nursing.J Clin Nurs.2013 Sep;22(17-18):2499-508. doi: 10.1111/j.1365-2702.2012.04295.x. Epub 2012 Nov 2.
- AIMS AND OBJECTIVES: To explore the effectiveness of wound care programme for emergency traumatic patient in Taiwan.BACKGROUND: Wound care is one of the most major issues for trauma patients at home. Wound infection has been alerted mostly on medical treatment. Little is known about how healthcare e
- PMID 23121467
Japanese Journal
- Noise statistics of phase-resolved optical coherence tomography imaging: single-and dual-beam-scan Doppler optical coherence tomography
- Makita Shuichi,Jaillon Franck,Jahan Israt,Yasuno Yoshiaki,巻田 修一,安野 嘉晃
- Optics Express 22(4), 4830-4848, 2014-02
- … In this paper, the statistical properties of phase shift between two OCT signals that contain additive random noises and speckle noises are presented. … As expected, phase shift noise in the case of the dual-beam-scan method is less than that for the single-beam method when the transversal sampling step is large. …
- NAID 120005418337
- 住民意識にみる公共事業効果の「神話」性とその構成要因 : 鞆の浦港湾架橋問題に関するアンケート調査結果を用いて
- 鈴木 晃志郎
- 歴史地理学 56(1), 1-20, 2014-01
- … This surveyincludes the 441 respondents out of 4,434 residents in Tamonoura area through random sampling. …
- NAID 120005423518
- Efficient Sampling Method for Monte Carlo Tree Search Problem
- TERAOKA Kazuki,HATANO Kohei,TAKIMOTO Eiji
- IEICE Transactions on Information and Systems E97.D(3), 392-398, 2014
- … We consider Monte Carlo tree search problem, a variant of Min-Max tree search problem where the score of each leaf is the expectation of some Bernoulli variables and not explicitly given but can be estimated through (random) playouts. …
- NAID 130003394853
Related Links
- random samplingとは。意味や和訳。[U]《統計学》任意[無作為]抽出法. - goo辞書は国語、英和、和英、中国語、百科事典等からまとめて探せる辞書検索サービスです。 ... gooのお知らせ gooヘルスケア「おもいやり食堂」 気になる ...
- This page contains user testimonials for the true random number service RANDOM.ORG, which offers true random numbers to anyone on the Internet. The randomness comes from atmospheric noise, which for many purposes is ...
★リンクテーブル★
| リンク元 | 「randomized」「無作為抽出」 |
| 関連記事 | 「random」「sampling」 |
「randomized」
- adj.
- ランダム化された、無作為化された、無作為抽出の
「無作為抽出」
「random」
- adj.
- ランダムな、無秩序な、無作為の
「sampling」
- n.
- 関
- sample