目次
WordNet
- change the order or arrangement of; "Dyslexics often transpose letters in a word" (同)commute, transpose
PrepTutorEJDIC
- …‘の'順序を変える / (数学で)〈数〉‘を'置換する
Wikipedia preview
出典(authority):フリー百科事典『ウィキペディア(Wikipedia)』「2015/05/22 16:53:32」(JST)
wiki en
For other uses, see Permutation (disambiguation).
"nPr" redirects here. For other uses, see NPR (disambiguation).
Each of the six rows is a different permutation of three distinct balls
In mathematics, the notion of permutation relates to the act of rearranging, or permuting, all the members of a set into some sequence or order (unlike combinations, which are selections of some members of the set where order is disregarded). For example, written as tuples, there are six permutations of the set {1,2,3}, namely: (1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,1,2), and (3,2,1). As another example, an anagram of a word, all of whose letters are different, is a permutation of its letters. The study of permutations of finite sets is a topic in the field of combinatorics.
Permutations occur, in more or less prominent ways, in almost every area of mathematics. They often arise when different orderings on certain finite sets are considered, possibly only because one wants to ignore such orderings and needs to know how many configurations are thus identified. For similar reasons permutations arise in the study of sorting algorithms in computer science.
The number of permutations of n distinct objects is n factorial usually written as n!, which means the product of all positive integers less than or equal to n.
In algebra and particularly in group theory, a permutation of a set S is defined as a bijection from S to itself. That is, it is a function from S to S for which every element occurs exactly once as an image value. This is related to the rearrangement of the elements of S in which each element s is replaced by the corresponding f(s). The collection of such permutations form a group called the symmetric group of S. The key to this group's structure is the fact that the composition of two permutations (performing two given rearrangements in succession) results in another rearrangement. Permutations may act on structured objects by rearranging their components, or by certain replacements (substitutions) of symbols.
In elementary combinatorics, the k-permutations, or partial permutations, are the ordered arrangements of k distinct elements selected from a set. When k is equal to the size of the set, these are the permutations of the set.
In the popular puzzle Rubik's cube invented in 1974 by Ernő Rubik, each turn of the puzzle faces creates a permutation of the surface colors.
Contents
- 1 History
- 2 Definition and one-line notation
- 3 Other uses of the term permutation
- 3.1 k-permutations of n
- 3.2 Permutations with repetition
- 3.3 Permutations of multisets
- 3.4 Circular permutations
- 4 Permutations in group theory
- 4.1 Cycle notation
- 4.2 Abstract groups vs. permutations vs. group actions
- 4.3 Product and inverse
- 4.4 Properties
- 4.4.1 Matrix representation
- 4.4.2 Permutation of components of a sequence
- 5 Permutations of totally ordered sets
- 5.1 Ascents, descents, runs and excedances
- 5.2 Canonical cycle notation (aka standard form)
- 5.3 Foata's transition lemma (or the fundamental bijection)
- 5.4 Inversions
- 6 Permutations in computing
- 6.1 Numbering permutations
- 6.2 Algorithms to generate permutations
- 6.2.1 Random generation of permutations
- 6.2.2 Generation in lexicographic order
- 6.2.3 Generation with minimal changes
- 6.2.4 Meandric permutations
- 6.3 Software implementations
- 6.3.1 Calculator functions
- 6.3.2 Spreadsheet functions
- 6.4 Applications
- 7 See also
- 8 Notes
- 9 References
- 10 External links
History
The rule to determine the number of permutations of n objects was known in Indian culture at least as early as around 1150: the Lilavati by the Indian mathematician Bhaskara II contains a passage that translates to
The product of multiplication of the arithmetical series beginning and increasing by unity and continued to the number of places, will be the variations of number with specific figures.[1]
Fabian Stedman in 1677 described factorials when explaining the number of permutations of bells in change ringing. Starting from two bells: "first, two must be admitted to be varied in two ways" which he illustrates by showing 1 2 and 2 1.[2] He then explains that with three bells there are "three times two figures to be produced out of three" which again is illustrated. His explanation involves "cast away 3, and 1.2 will remain; cast away 2, and 1.3 will remain; cast away 1, and 2.3 will remain".[3] He then moves on to four bells and repeats the casting away argument showing that there will be four different sets of three. Effectively this is an recursive process. He continues with five bells using the "casting away" method and tabulates the resulting 120 combinations.[4] At this point he gives up and remarks:
Now the nature of these methods is such, that the changes on one number comprehends the changes on all lesser numbers, ... insomuch that a compleat Peal of changes on one number seemeth to be formed by uniting of the compleat Peals on all lesser numbers into one entire body;[5]
Stedman widens the consideration of permutations; he goes on to consider the number of permutations of the letters of the alphabet and horses from a stable of 20.[6]
A first case in which seemingly unrelated mathematical questions were studied with the help of permutations occurred around 1770, when Joseph Louis Lagrange, in the study of polynomial equations, observed that properties of the permutations of the roots of an equation are related to the possibilities to solve it. This line of work ultimately resulted, through the work of Évariste Galois, in Galois theory, which gives a complete description of what is possible and impossible with respect to solving polynomial equations (in one unknown) by radicals. In modern mathematics there are many similar situations in which understanding a problem requires studying certain permutations related to it.
Definition and one-line notation
There are two equivalent common ways of regarding permutations, sometimes called the "active" and "passive" forms, or in older terminology "substitutions" and "permutations".[7] Which form is preferable depends on the type of questions being asked in a given discipline.
The "active" way to regard permutations of a set S (finite or infinite) is to define them as the bijections from S to itself. Thus, the permutations are thought of as functions which can be composed with each other, forming groups of permutations. From this viewpoint, the elements of S have no internal structure and are just labels for the objects being moved: one may refer to permutations of any set of n elements as "permutations on n letters".
In Cauchy's two-line notation,[8] one lists the elements of S in the first row, and for each one its image below it in the second row. For instance, a particular permutation of the set S = {1,2,3,4,5} can be written as:

this means that σ satisfies σ(1)=2, σ(2)=5, σ(3)=4, σ(4)=3, and σ(5)=1. The elements of S may appear in any order in the first row. This permutation could also be written as:

The "passive" way to regard a permutation of the set S is an ordered arrangement (or listing, or linearly ordered arrangement, or sequence without repetition) of the elements of S. This is related to the active form as follows. If there is a "natural" order for the elements of S,[9] say , then one uses this for the first row of the two-line notation:

Under this assumption, one may omit the first row and write the permutation in one-line notation as , that is, an ordered arrangement of S.[10][11] Care must be taken to distinguish one-line notation from the cycle notation described later. In mathematics literature, a common usage is to omit parentheses for one-line notation, while using them for cycle notation. The one-line notation is also called the word representation of a permutation.[12] The example above would then be 2 5 4 3 1 since the natural order 1 2 3 4 5 would be assumed for the first row. (It is typical to use commas to separate these entries only if some have two or more digits.) This form is more compact, and is common in elementary combinatorics and computer science. It is especially useful in applications where the elements of S or the permutations are to be compared as larger or smaller.
There are n! permutations of a finite set S having n elements.
Other uses of the term permutation
The concept of a permutation as an ordered arrangement admits several generalizations that are not permutations but have been called permutations in the literature.
k-permutations of n
A weaker meaning of the term "permutation", sometimes used in elementary combinatorics texts, designates those ordered arrangements in which no element occurs more than once, but without the requirement of using all the elements from a given set. These are not permutations except in special cases, but are natural generalizations of the ordered arrangement concept. Indeed, this use often involves considering arrangements of a fixed length k of elements taken from a given set of size n, in other words, these k-permutations of n are the different ordered arrangements of a k-element subset of an n-set (sometimes called variations in the older literature.[13]) These objects are also known as partial permutations or as sequences without repetition, terms that avoid confusion with the other, more common, meaning of "permutation". The number of such -permutations of is denoted variously by such symbols as , , , , or , and its value is given by the product[14]
- ,
which is 0 when k > n, and otherwise is equal to
The product is well defined without the assumption that is a non-negative integer and is of importance outside combinatorics as well; it is known as the Pochhammer symbol or as the -th falling factorial power of .
This usage of the term "permutation" is closely related to the term "combination". A k-element combination of an n-set S is a k element subset of S, the elements of which are not ordered. By taking all the k element subsets of S and ordering each of them in all possible ways we obtain all the k-permutations of S. The number of k-combinations of an n-set, C(n,k), is therefore related to the number of k-permutations of n by:
These numbers are also known as binomial coefficients and denoted .
Permutations with repetition
Ordered arrangements of the elements of a set S of length n where repetition is allowed are called n-tuples, but have sometimes been referred to as permutations with repetition although they are not permutations in general. They are also called words over the alphabet S in some contexts. If the set S has k elements, the number of n-tuples over S is:
There is no restriction on how often an element can appear in an n-tuple, but if restrictions are placed on how often an element can appear, this formula is no longer valid.
Permutations of multisets
Permutations of multisets
If M is a finite multiset, then a multiset permutation is an ordered arrangement of elements of M in which each element appears exactly as often as is its multiplicity in M. An anagram of a word having some repeated letters is an example of a multiset permutation.[15] If the multiplicities of the elements of M (taken in some order) are , , ..., and their sum (i.e., the size of M) is n, then the number of multiset permutations of M is given by the multinomial coefficient,[16]
For example, the number of distinct anagrams of the word MISSISSIPPI is:[17]
- .
A k-permutation of a multiset M is a sequence of length k of elements of M in which each element appears at most its multiplicity in M times (an element's repetition number).
Circular permutations
Permutations, when considered as arrangements, are sometimes referred to as linearly ordered arrangements. In these arrangements there is a first element, a second element, and so on. If, however, the objects are arranged in a circular manner this distinguished ordering no longer exists, that is, there is no "first element" in the arrangement, any element can be considered as the start of the arrangement. The arrangements of objects in a circular manner are called circular permutations.[18][19] These can be formally defined as equivalence classes of ordinary permutations of the objects, for the equivalence relation generated by moving the final element of the linear arrangement to its front.
Two circular permutations are equivalent if one can be rotated into the other (that is, cycled without changing the relative positions of the elements). The following two circular permutations on four letters are considered to be the same.
1 4
4 3 2 1
2 3
The circular arrangements are to be read counterclockwise, so the following two are not equivalent since no rotation can bring one to the other.
1 1
4 3 3 4
2 2
The number of circular permutations of a set S with n elements is (n - 1)!.
Permutations in group theory
Main article: Symmetric group
The set of all permutations of any given set S forms a group, with the composition of maps as the product operation and the identity function as the neutral element of the group. This is the symmetric group of S, denoted by Sym(S). Up to isomorphism, this symmetric group only depends on the cardinality of the set (called the degree of the group), so the nature of elements of S is irrelevant for the structure of the group. Symmetric groups have been studied mostly in the case of finite sets, so, confined to this case, one can assume without loss of generality that S = {1,2,...,n} for some natural number n. This is then the symmetric group of degree n, usually written as Sn.
Any subgroup of a symmetric group is called a permutation group. By Cayley's theorem any group is isomorphic to some permutation group, and every finite group to a subgroup of some finite symmetric group.
Cycle notation
This alternative notation describes the effect of repeatedly applying the permutation, thought of as a function from a set onto itself. It expresses the permutation as a product of cycles corresponding to the orbits of the permutation; since distinct orbits are disjoint, this is referred to as "decomposition into disjoint cycles".[20]
Starting from some element x of S, one writes the sequence (x σ(x) σ(σ(x)) ...) of successive images under σ, until the image returns to x, at which point one closes the parenthesis rather than repeat x. The set of values written down forms the orbit (under σ) of x, and the parenthesized expression gives the corresponding cycle of σ. One then continues by choosing a new element y of S outside the previous orbit and writing down the cycle starting at y; and so on until all elements of S are written in cycles. Since for every new cycle the starting point can be chosen in different ways, there are in general many different cycle notations for the same permutation; for the example above one has:

A cycle (x) of length 1 occurs when σ(x) = x, and is commonly omitted from the cycle notation, provided the set S is clear: for any element x ∈ S not appearing in a cycle, one implicitly assumes σ(x) = x.[21] The identity permutation, which consists only of 1-cycles, can be denoted by a single 1-cycle (x), by the number 1, or by id.[22][23]
A cycle (x1 x2 ... xk) of length k is called a k-cycle. Written by itself, it denotes a permutation in its own right, which maps xi to xi+1 for i < k, and xk to x1, while implicitly mapping all other elements of S to themselves (omitted 1-cycles). Therefore the individual cycles in the cycle notation can be interpreted as factors in a composition product. Since the orbits are disjoint, the corresponding cycles commute under composition, and so can be written in any order. The cycle decomposition is essentially unique: apart from the reordering the cycles in the product, there are no other ways to write σ as a product of cycles. Each individual cycle can be written in different ways, as in the example above where (5 1 2) and (1 2 5) and (2 5 1) all denote the same cycle, though note that (5 2 1) denotes a different cycle.
An element in a 1-cycle (x), corresponding to σ(x) = x, is called a fixed point of the permutation σ. A permutation with no fixed points is called a derangement. Cycles of length two are called transpositions; such permutations merely exchange the place of two elements, implicitly leaving the others fixed. Since the orbits of a permutation partition the set S, for a finite set of size n, the lengths of the cycles of a permutation σ form a partition of n called the cycle type of σ. There is a "1" in the cycle type for every fixed point of σ, a "2" for every transposition, and so on. The cycle type of β = (1 2 5)(3 4)(6 8)(7), is (3,2,2,1) which is sometimes written in a more compact form as (11,22,31).
The number of n-permutations with k disjoint cycles is the signless Stirling number of the first kind, denoted by .[24]
Abstract groups vs. permutations vs. group actions
Permutation groups have more structure than abstract groups, and different realizations of a group as a permutation group need not be equivalent as permutations. For instance S3 is naturally a permutation group, in which any transposition has cycle type (2,1); but the proof of Cayley's theorem realizes S3 as a subgroup of S6 (namely the permutations of the 6 elements of S3 itself), in which permutation group transpositions have cycle type (2,2,2). Finding the minimal-order symmetric group containing a subgroup isomorphic to a given group (sometimes called minimal faithful degree representation) is a rather difficult problem.[25][26] So in spite of Cayley's theorem, the study of permutation groups differs from the study of abstract groups, being a branch of representation theory.
Much of the power of permutations can be regained in an abstract setting by considering group actions instead.[27] A group action actually permutes the elements of a set according to the recipe provided by the abstract group. For example, S3 acts faithfully and transitively (by permuting) a set with exactly three elements.
Product and inverse
The product of two permutations is defined as their composition as functions, in other words σ·π is the function that maps any element x of the set to σ(π(x)). Note that the rightmost permutation is applied to the argument first, [28] because of the way function application is written. Some authors prefer the leftmost factor acting first, [29] [30] [31] but to that end permutations must be written to the right of their argument, for instance as an exponent, where σ acting on x is written xσ; then the product is defined by xσ·π = (xσ)π. However this gives a different rule for multiplying permutations; this article uses the definition where the rightmost permutation is applied first.
Since the composition of two bijections always gives another bijection, the product of two permutations is again a permutation. In two-line notation, the product of two permutations is obtained by rearranging the columns of the second (leftmost) permutation so that its first row is identical with the second row of the first (rightmost) permutation. The product can then be written as the first row of the first permutation over the second row of the modified second permutation. For example, given the permutations,
the product QP is:
In cyclic notation this same product would be given by:
Since function composition is associative, so is the product operation on permutations: (σ·π)·ρ = σ·(π·ρ). Therefore, products of more than two permutations are usually written without adding parentheses to express grouping; they are also usually written without a dot or other sign to indicate multiplication.
The identity permutation, which maps every element of the set to itself, is the neutral element for this product. In two-line notation, the identity is
Since bijections have inverses, so do permutations, and the inverse σ−1 of σ is again a permutation. Explicitly, whenever σ(x)=y one also has σ−1(y)=x. In two-line notation the inverse can be obtained by interchanging the two lines (and sorting the columns if one wishes the first line to be in a given order). For instance
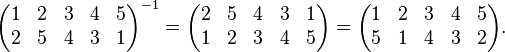
In cycle notation one can reverse the order of the elements in each cycle to obtain a cycle notation for its inverse. Thus,
Having an associative product, a neutral element, and inverses for all its elements, makes the set of all permutations of S into a group, called the symmetric group of S.
Properties
Every permutation of a finite set can be expressed as the product of transpositions.[32] Moreover, although many such expressions for a given permutation may exist, there can never be among them both expressions with an even number and expressions with an odd number of transpositions. All permutations are then classified as even or odd, according to the parity of the transpositions in any such expression.
Composition of permutations corresponds to multiplication of permutation matrices.
Multiplying permutations written in cycle notation follows no easily described pattern, and the cycles of the product can be entirely different from those of the permutations being composed. However the cycle structure is preserved in the special case of conjugating a permutation σ by another permutation π, which means forming the product π·σ·π−1. Here the cycle notation of the result can be obtained by taking the cycle notation for σ and applying π to all the entries in it.[33]
Matrix representation
One can represent a permutation of {1, 2, ..., n} as an n×n matrix. There are two natural ways to do so, but only one for which multiplications of matrices corresponds to multiplication of permutations in the same order: this is the one that associates to σ the matrix M whose entry Mi,j is 1 if i = σ(j), and 0 otherwise. The resulting matrix has exactly one entry 1 in each column and in each row, and is called a permutation matrix.
Here (file) is a list of these matrices for permutations of 4 elements. The Cayley table on the right shows these matrices for permutations of 3 elements.
Permutation of components of a sequence
As with any group, one can consider actions of a symmetric group on a set, and there are many ways in which such an action can be defined. For the symmetric group of {1, 2, ..., n} there is one particularly natural action, namely the action by permutation on the set Xn of sequences of n symbols taken from some set X. As with the matrix representation, there are two natural ways in which the result of permuting a sequence (x1,x2,...,xn) by σ can be defined, but only one is compatible with the multiplication of permutations (so as to give a left action of the symmetric group on Xn); with the multiplication rule used in this article this is the one given by
This means that each component xi ends up at position σ(i) in the sequence permuted by σ.
Permutations of totally ordered sets
In some applications, the elements of the set being permuted will be compared with each other. This requires that the set S has a total order so that any two elements can be compared. The set {1, 2, ..., n} is totally ordered by the usual "≤" relation and so it is the most frequently used set in these applications, but in general, any totally ordered set will do. In these applications, the ordered arrangement view of a permutation is needed to talk about the positions in a permutation.
Here are a number of properties that are directly related to the total ordering of S.
Ascents, descents, runs and excedances
An ascent of a permutation σ of n is any position i < n where the following value is bigger than the current one. That is, if σ = σ1σ2...σn, then i is an ascent if σi < σi+1.
For example, the permutation 3452167 has ascents (at positions) 1,2,5,6.
Similarly, a descent is a position i < n with σi > σi+1, so every i with either is an ascent or is a descent of σ.
An ascending run of a permutation is a nonempty increasing contiguous subsequence of the permutation that cannot be extended at either end; it corresponds to a maximal sequence of successive ascents (the latter may be empty: between two successive descents there is still an ascending run of length 1). By contrast an increasing subsequence of a permutation is not necessarily contiguous: it is an increasing sequence of elements obtained from the permutation by omitting the values at some positions. For example, the permutation 2453167 has the ascending runs 245, 3, and 167, while it has an increasing subsequence 2367.
If a permutation has k − 1 descents, then it must be the union of k ascending runs.[34]
The number of permutations of n with k ascents is (by definition) the Eulerian number ; this is also the number of permutations of n with k descents. Some authors however define the Eulerian number as the number of permutations with k ascending runs, which corresponds to k-1 descents.[35]
An excedance of a permutation σ1σ2...σn in an index j such that σj > j. If the inequality is not strict, i.e. σj ≥ j, then j is called a weak excedance. The number of n-permutations with k excedances coincides with the number of n-permutations with k descents.[36]
Canonical cycle notation (aka standard form)
In some combinatorial contexts it useful to fix a certain order or the elements in the cycles and of the (disjoint) cycles themselves. Miklós Bóna calls the following ordering choices the canonical cycle notation:
- in each cycle the largest element is listed first
- the cycles are sorted in increasing order of their first element
For example, (312)(54)(8)(976) is a permutation in canonical cycle notation.[37] Note that the canonical cycle notation does not omit one-cycles.
Richard P. Stanley calls the same choice of representation the "standard representation" of a permutation.[38] and Martin Aigner uses the term "standard form" for the same notion.[12] Sergey Kitaev also uses the "standard form" terminology, but reverses both choices, i.e. each cycle lists its least element first and the cycles are sorted in decreasing order of their least/first elements.[39] In the remainder of this article, we use the first of these dual forms as the standard/canonical one.
Foata's transition lemma (or the fundamental bijection)
A natural question arises as to the relationship of the one-line and the canonical cycle notation. For example, considering the permutation (2)(31), which is in canonical cycle notation, if we erase its cycle parentheses, we obtain a different permutation in one-line notation, namely 231. (The permutation (2)(31) is actually 321 in one-line notation.) Foata's transition lemma establishes the nature of this correspondence as a bijection on the set of n-permutations (to itself).[40] Richard P. Stanley calls this correspondence the fundamental bijection.[38]
Let be the parentheses-erasing transformation. The inverse of is a bit less intuitive. Starting with the one-line notation , the first cycle in canonical cycle notation must start with . As long as the subsequent elements are smaller than , we are in the same cycle. The second cycle starts at the smallest index such that . In other words, is larger than everything else to its left, so it is called a left-to-right maximum. Every cycle in the canonical cycle notation starts with a left-to-right maximum.[40]
For example, in the one-line notation 312548976, 5 is the first element larger than 3, so the first cycle must be (312). Then 8 is the next element larger than 5, so the second cycle is (54). Since 9 is larger than 8, (8) is a cycle by itself. Finally, 9 is larger than all the remaining elements to its right, so the last cycle is (976).
As a first corollary, the number of n-permutations with exactly k left-to-right maxima is also equal to the signless Stirling number of the first kind, . Furthermore, Foata's mapping takes an n-permutation with k-weak excedances to an n-permutations with k − 1 ascents.[40] For example, (2)(31) = 321 has two weak excedances (at index 1 and 2), whereas f(321)=231 has one ascent (at index 1, i.e. from 2 to 3).
Inversions
Main article: Inversion (discrete mathematics)
In the 15 puzzle the goal is to get the squares in ascending order. Initial positions which have an odd number of inversions are impossible to solve.[41]
An inversion of a permutation σ is a pair (i,j) of positions where the entries of a permutation are in the opposite order: and .[42] So a descent is just an inversion at two adjacent positions. For example, the permutation σ = 23154 has three inversions: (1,3), (2,3), (4,5), for the pairs of entries (2,1), (3,1), (5,4).
Sometimes an inversion is defined as the pair of values (σi,σj) itself whose order is reversed; this makes no difference for the number of inversions, and this pair (reversed) is also an inversion in the above sense for the inverse permutation σ−1. The number of inversions is an important measure for the degree to which the entries of a permutation are out of order; it is the same for σ and for σ−1. To bring a permutation with k inversions into order (i.e., transform it into the identity permutation), by successively applying (right-multiplication by) adjacent transpositions, is always possible and requires a sequence of k such operations. Moreover any reasonable choice for the adjacent transpositions will work: it suffices to choose at each step a transposition of i and i + 1 where i is a descent of the permutation as modified so far (so that the transposition will remove this particular descent, although it might create other descents). This is so because applying such a transposition reduces the number of inversions by 1; also note that as long as this number is not zero, the permutation is not the identity, so it has at least one descent. Bubble sort and insertion sort can be interpreted as particular instances of this procedure to put a sequence into order. Incidentally this procedure proves that any permutation σ can be written as a product of adjacent transpositions; for this one may simply reverse any sequence of such transpositions that transforms σ into the identity. In fact, by enumerating all sequences of adjacent transpositions that would transform σ into the identity, one obtains (after reversal) a complete list of all expressions of minimal length writing σ as a product of adjacent transpositions.
The number of permutations of n with k inversions is expressed by a Mahonian number,[43] it is the coefficient of Xk in the expansion of the product
which is also known (with q substituted for X) as the q-factorial [n]q! . The expansion of the product appears in Necklace (combinatorics).
Permutations in computing
Numbering permutations
One way to represent permutations of n is by an integer N with 0 ≤ N < n!, provided convenient methods are given to convert between the number and the representation of a permutation as an ordered arrangement (sequence). This gives the most compact representation of arbitrary permutations, and in computing is particularly attractive when n is small enough that N can be held in a machine word; for 32-bit words this means n ≤ 12, and for 64-bit words this means n ≤ 20. The conversion can be done via the intermediate form of a sequence of numbers dn, dn−1, ..., d2, d1, where di is a non-negative integer less than i (one may omit d1, as it is always 0, but its presence makes the subsequent conversion to a permutation easier to describe). The first step then is to simply express N in the factorial number system, which is just a particular mixed radix representation, where for numbers up to n! the bases for successive digits are n, n − 1, ..., 2, 1. The second step interprets this sequence as a Lehmer code or (almost equivalently) as an inversion table.
| i \ σi | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Lehmer code |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | × | × | • | d9 = 5 | |||
| 2 | × | × | • | d8 = 2 | ||||||
| 3 | × | × | × | × | × | • | d7 = 5 | |||
| 4 | • | d6 = 0 | ||||||||
| 5 | × | • | d5 = 1 | |||||||
| 6 | × | × | × | • | d4 = 3 | |||||
| 7 | × | × | • | d3 = 2 | ||||||
| 8 | • | d2 = 0 | ||||||||
| 9 | • | d1 = 0 | ||||||||
| inversion table | 3 | 6 | 1 | 2 | 4 | 0 | 2 | 0 | 0 |
In the Lehmer code for a permutation σ, the number dn represents the choice made for the first term σ1, the number dn−1 represents the choice made for the second term σ2 among the remaining n − 1 elements of the set, and so forth. More precisely, each dn+1−i gives the number of remaining elements strictly less than the term σi. Since those remaining elements are bound to turn up as some later term σj, the digit dn+1−i counts the inversions (i,j) involving i as smaller index (the number of values j for which i < j and σi > σj). The inversion table for σ is quite similar, but here dn+1−k counts the number of inversions (i,j) where k = σj occurs as the smaller of the two values appearing in inverted order.[44] Both encodings can be visualized by an n by n Rothe diagram[45] (named after Heinrich August Rothe) in which dots at (i,σi) mark the entries of the permutation, and a cross at (i,σj) marks the inversion (i,j); by the definition of inversions a cross appears in any square that comes both before the dot (j,σj) in its column, and before the dot (i,σi) in its row. The Lehmer code lists the numbers of crosses in successive rows, while the inversion table lists the numbers of crosses in successive columns; it is just the Lehmer code for the inverse permutation, and vice versa.
To effectively convert a Lehmer code dn, dn−1, ..., d2, d1 into a permutation of an ordered set S, one can start with a list of the elements of S in increasing order, and for i increasing from 1 to n set σi to the element in the list that is preceded by dn+1−i other ones, and remove that element from the list. To convert an inversion table dn, dn−1, ..., d2, d1 into the corresponding permutation, one can traverse the numbers from d1 to dn while inserting the elements of S from largest to smallest into an initially empty sequence; at the step using the number d from the inversion table, the element from S inserted into the sequence at the point where it is preceded by d elements already present. Alternatively one could process the numbers from the inversion table and the elements of S both in the opposite order, starting with a row of n empty slots, and at each step place the element from S into the empty slot that is preceded by d other empty slots.
Converting successive natural numbers to the factorial number system produces those sequences in lexicographic order (as is the case with any mixed radix number system), and further converting them to permutations preserves the lexicographic ordering, provided the Lehmer code interpretation is used (using inversion tables, one gets a different ordering, where one starts by comparing permutations by the place of their entries 1 rather than by the value of their first entries). The sum of the numbers in the factorial number system representation gives the number of inversions of the permutation, and the parity of that sum gives the signature of the permutation. Moreover the positions of the zeroes in the inversion table give the values of left-to-right maxima of the permutation (in the example 6, 8, 9) while the positions of the zeroes in the Lehmer code are the positions of the right-to-left minima (in the example positions the 4, 8, 9 of the values 1, 2, 5); this allows computing the distribution of such extrema among all permutations. A permutation with Lehmer code dn, dn−1, ..., d2, d1 has an ascent n − i if and only if di ≥ di+1.
Algorithms to generate permutations
In computing it may be required to generate permutations of a given sequence of values. The methods best adapted to do this depend on whether one wants some randomly chosen permutations, or all permutations, and in the latter case if a specific ordering is required. Another question is whether possible equality among entries in the given sequence is to be taken into account; if so, one should only generate distinct multiset permutations of the sequence.
An obvious way to generate permutations of n is to generate values for the Lehmer code (possibly using the factorial number system representation of integers up to n!), and convert those into the corresponding permutations. However, the latter step, while straightforward, is hard to implement efficiently, because it requires n operations each of selection from a sequence and deletion from it, at an arbitrary position; of the obvious representations of the sequence as an array or a linked list, both require (for different reasons) about n2/4 operations to perform the conversion. With n likely to be rather small (especially if generation of all permutations is needed) that is not too much of a problem, but it turns out that both for random and for systematic generation there are simple alternatives that do considerably better. For this reason it does not seem useful, although certainly possible, to employ a special data structure that would allow performing the conversion from Lehmer code to permutation in O(n log n) time.
Random generation of permutations
Main article: Fisher–Yates shuffle
For generating random permutations of a given sequence of n values, it makes no difference whether one applies a randomly selected permutation of n to the sequence, or chooses a random element from the set of distinct (multiset) permutations of the sequence. This is because, even though in case of repeated values there can be many distinct permutations of n that result in the same permuted sequence, the number of such permutations is the same for each possible result. Unlike for systematic generation, which becomes unfeasible for large n due to the growth of the number n!, there is no reason to assume that n will be small for random generation.
The basic idea to generate a random permutation is to generate at random one of the n! sequences of integers d1,d2,...,dn satisfying 0 ≤ di < i (since d1 is always zero it may be omitted) and to convert it to a permutation through a bijective correspondence. For the latter correspondence one could interpret the (reverse) sequence as a Lehmer code, and this gives a generation method first published in 1938 by Ronald A. Fisher and Frank Yates.[46] While at the time computer implementation was not an issue, this method suffers from the difficulty sketched above to convert from Lehmer code to permutation efficiently. This can be remedied by using a different bijective correspondence: after using di to select an element among i remaining elements of the sequence (for decreasing values of i), rather than removing the element and compacting the sequence by shifting down further elements one place, one swaps the element with the final remaining element. Thus the elements remaining for selection form a consecutive range at each point in time, even though they may not occur in the same order as they did in the original sequence. The mapping from sequence of integers to permutations is somewhat complicated, but it can be seen to produce each permutation in exactly one way, by an immediate induction. When the selected element happens to be the final remaining element, the swap operation can be omitted. This does not occur sufficiently often to warrant testing for the condition, but the final element must be included among the candidates of the selection, to guarantee that all permutations can be generated.
The resulting algorithm for generating a random permutation of a[0], a[1], ..., a[n − 1] can be described as follows in pseudocode:
- for i from n downto 2
- do di ← random element of { 0, ..., i − 1 }
- swap a[di] and a[i − 1]
This can be combined with the initialization of the array a[i] = i as follows:
- for i from 0 to n−1
- do di+1 ← random element of { 0, ..., i }
- a[i] ← a[di+1]
- a[di+1] ← i
If di+1 = i, the first assignment will copy an uninitialized value, but the second will overwrite it with the correct value i.
Generation in lexicographic order
There are many ways to systematically generate all permutations of a given sequence.[47] One classical algorithm, which is both simple and flexible, is based on finding the next permutation in lexicographic ordering, if it exists. It can handle repeated values, for which case it generates the distinct multiset permutations each once. Even for ordinary permutations it is significantly more efficient than generating values for the Lehmer code in lexicographic order (possibly using the factorial number system) and converting those to permutations. To use it, one starts by sorting the sequence in (weakly) increasing order (which gives its lexicographically minimal permutation), and then repeats advancing to the next permutation as long as one is found. The method goes back to Narayana Pandita in 14th century India, and has been frequently rediscovered ever since.[48]
The following algorithm generates the next permutation lexicographically after a given permutation. It changes the given permutation in-place.
- Find the largest index k such that a[k] < a[k + 1]. If no such index exists, the permutation is the last permutation.
- Find the largest index l greater than k such that a[k] < a[l].
- Swap the value of a[k] with that of a[l].
- Reverse the sequence from a[k + 1] up to and including the final element a[n].
For example, given the sequence [1, 2, 3, 4] which starts in a weakly increasing order, and given that the index is zero-based, the steps are as follows:
- Index k = 2, because 3 is placed at an index that satisfies condition of being the largest index that is still less than a[k + 1] which is 4.
- Index l = 3, because 4 is the only value in the sequence that is greater than 3 in order to satisfy the condition a[k] < a[l].
- The values of a[2] and a[3] are swapped to form the new sequence [1,2,4,3].
- The sequence after k-index a[2] to the final element is reversed. Because only one value lies after this index (the 3), the sequence remains unchanged in this instance. Thus the lexicographic successor of the initial state is permuted: [1,2,4,3].
Following this algorithm, the next lexicographic permutation will be [1,3,2,4], and the 24th permutation will be [4,3,2,1] at which point a[k] < a[k + 1] does not exist, indicating that this is the last permutation.
Generation with minimal changes
Main articles: Steinhaus–Johnson–Trotter algorithm and Heap's algorithm
An alternative to the above algorithm, the Steinhaus–Johnson–Trotter algorithm, generates an ordering on all the permutations of a given sequence with the property that any two consecutive permutations in its output differ by swapping two adjacent values. This ordering on the permutations was known to 17th-century English bell ringers, among whom it was known as "plain changes". One advantage of this method is that the small amount of change from one permutation to the next allows the method to be implemented in constant time per permutation. The same can also easily generate the subset of even permutations, again in constant time per permutation, by skipping every other output permutation.[48]
An alternative to Steinhaus–Johnson–Trotter is Heap's algorithm,[49] said by Robert Sedgewick in 1977 to be the fastest algorithm of generating permutations in applications.[47]
Meandric permutations
Meandric systems give rise to meandric permutations, a special subset of alternate permutations. An alternate permutation of the set {1,2,...,2n} is a cyclic permutation (with no fixed points) such that the digits in the cyclic notation form alternate between odd and even integers. Meandric permutations are useful in the analysis of RNA secondary structure. Not all alternate permutations are meandric. A modification of Heap's algorithm has been used to generate all alternate permutations of order n (that is, of length 2n) without generating all (2n)! permutations.[50] Generation of these alternate permutations is needed before they are analyzed to determine if they are meandric or not.
The algorithm is recursive. The following table exhibits a step in the procedure. In the previous step, all alternate permutations of length 5 have been generated. Three copies of each of these have a "6" added to the right end, and then a different transposition involving this last entry and a previous entry in an even position is applied (including the identity, i.e., no transposition).
| Previous sets | Transposition of digits | Alternate permutations |
|---|---|---|
| 1-2-3-4-5-6 | 1-2-3-4-5-6 | |
| 1-2-3-4-5-6 | 4,6 | 1-2-3-6-5-4 |
| 1-2-3-4-5-6 | 2,6 | 1-6-3-4-5-2 |
| 1-2-5-4-3-6 | 1-2-5-4-3-6 | |
| 1-2-5-4-3-6 | 4,6 | 1-2-5-6-3-4 |
| 1-2-5-4-3-6 | 2,6 | 1-6-5-4-3-2 |
| 1-4-3-2-5-6 | 1-4-3-2-5-6 | |
| 1-4-3-2-5-6 | 2,6 | 1-4-3-6-5-2 |
| 1-4-3-2-5-6 | 4,6 | 1-6-3-2-5-4 |
| 1-4-5-2-3-6 | 1-4-5-2-3-6 | |
| 1-4-5-2-3-6 | 2,6 | 1-4-5-6-3-2 |
| 1-4-5-2-3-6 | 4,6 | 1-6-5-2-3-4 |
Software implementations
Calculator functions
Many scientific calculators and computing software have a built-in function for calculating the number of k-permutations of n.
- Casio and TI calculators: nPr
- HP calculators: PERM[51]
- Mathematica: FactorialPower
Spreadsheet functions
Most spreadsheet software also provides a built-in function for calculating the number of k-permutations of n, called PERMUT in many popular spreadsheets.
Applications
Permutations are used in the interleaver component of the error detection and correction algorithms, such as turbo codes, for example 3GPP Long Term Evolution mobile telecommunication standard uses these ideas (see 3GPP technical specification 36.212 [52]). Such applications raise the question of fast generation of permutations satisfying certain desirable properties. One of the methods is based on the permutation polynomials. Also as a base for optimal hashing in Unique Permutation Hashing.[53]
See also
| Mathematics portal |
- Alternating permutation
- Binomial coefficient
- Combination
- Combinatorics
- Convolution
- Cyclic order
- Cyclic permutation
- Even and odd permutations
- Factorial number system
- Josephus permutation
- Levi-Civita symbol
- List of permutation topics
- Major index
- Necklace (combinatorics)
- Permutation group
- Permutation pattern
- Permutation polynomial
- Permutation representation (symmetric group)
- Probability
- Random permutation
- Rencontres numbers
- Sorting network
- Substitution cipher
- Superpattern
- Symmetric group
- Twelvefold way
- Weak order of permutations
Notes
| This article has an unclear citation style. The references used may be made clearer with a different or consistent style of citation, footnoting, or external linking. (April 2015) |
- ^ N. L. Biggs, The roots of combinatorics, Historia Math. 6 (1979) 109−136
- ^ Stedman 1677, p. 4.
- ^ Stedman 1677, p. 5.
- ^ Stedman 1677, pp. 6—7.
- ^ Stedman 1677, p. 8.
- ^ Stedman 1677, pp. 13—18.
- ^ Cameron (1994) p. 29, footnote 3
- ^ Wussing, Hans (2007), The Genesis of the Abstract Group Concept: A Contribution to the History of the Origin of Abstract Group Theory, Courier Dover Publications, p. 94, ISBN 9780486458687,
Cauchy used his permutation notation—in which the arrangements are written one below the other and both are enclosed in parentheses—for the first time in 1815.
- ^ The order is often implicitly understood. A set of integers is naturally written from smallest to largest; a set of letters is written in lexicographic order. For other sets, a natural order needs to be specified explicitly.
- ^ Bogart 1990, p. 17
- ^ Gerstein 1987, p. 217
- ^ a b Martin Aigner (2007). A Course in Enumeration. Springer GTM 238. pp. 24–25. ISBN 978-3-540-39035-0.
- ^ More precisely, variations without repetition. The term is still common in other languages and appears in modern English most often in translation.
- ^ Charalambides, Ch A. (2002). Enumerative Combinatorics. CRC Press. p. 42. ISBN 978-1-58488-290-9.
- ^ The natural order in this example is the order of the letters in the original word.
- ^ Brualdi 2010, p. 46, Theorem 2.4.2
- ^ Brualdi 2010, p. 47
- ^ Brualdi 2010, p. 39
- ^ In older texts circular permutation was sometimes used as a synonym for cyclic permutation, but this is no longer done. See Carmichael (1956, p. 7)
- ^ Due to the likely possibility of confusion, cycle notation is not used in conjunction with one-line notation (sequences) for permutations.
- ^ Hall 1959, p. 54
- ^ Rotman 2002, p. 41
- ^ Bogart 1990, p. 487
- ^ Miklos Bona (2012). Combinatorics of Permutations, Second Edition. CRC Press. pp. 97–103. ISBN 978-1-4398-5051-0.
- ^ Johnson, D. L. (1971). "Minimal Permutation Representations of Finite Groups". American Journal of Mathematics 93 (4): 857. doi:10.2307/2373739. JSTOR 2373739. edit
- ^ David Easdown (1992). "Minimal Faithful Permutation and Transformation Representations of Groups and Semigroups". In L.A. Bokut, Yu L. Ershov , A.I. Kostrikin. Proceedings of the International Conference on Algebra Dedicated to the Memory of A.I. Malcev (Part 3). American Mathematical Soc. pp. 75–84. ISBN 0-8218-5138-1.
- ^ I. Martin Isaacs (1994). Algebra: A Graduate Course. American Mathematical Soc. p. 42. ISBN 978-0-8218-4799-2.
- ^ Biggs, Norman L.; White, A. T. (1979). Permutation groups and combinatorial structures. Cambridge University Press. ISBN 0-521-22287-7.
- ^ Dixon, John D.; Mortimer, Brian (1996). Permutation Groups. Springer. ISBN 0-387-94599-7.
- ^ Cameron, Peter J. (1999). Permutation groups. Cambridge University Press. ISBN 0-521-65302-9.
- ^ Jerrum, M. (1986). "A compact representation of permutation groups". J. Algor. 7 (1): 60–78. doi:10.1016/0196-6774(86)90038-6.
- ^ Hall 1959, p. 60
- ^ Humphreys (1996), p. 84
- ^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bóna, 2004, p. 4f
- ^ Miklos Bona (2012). Combinatorics of Permutations, Second Edition. CRC Press. pp. 4–5. ISBN 978-1-4398-5051-0.
- ^ Miklos Bona (2012). Combinatorics of Permutations, Second Edition. CRC Press. p. 25. ISBN 978-1-4398-5051-0.
- ^ Miklos Bona (2012). Combinatorics of Permutations, Second Edition. CRC Press. p. 87. ISBN 978-1-4398-5051-0. [Note that the book has a typo/error here, as it gives (45) instead of (54).]
- ^ a b Richard P. Stanley (2012). Enumerative Combinatorics: Volume I, Second Edition. Cambridge University Press. p. 23. ISBN 978-1-107-01542-5.
- ^ Sergey Kitaev (2011). Patterns in Permutations and Words. Springer Science & Business Media. p. 119. ISBN 978-3-642-17333-2.
- ^ a b c Miklos Bona (2012). Combinatorics of Permutations, Second Edition. CRC Press. pp. 109–110. ISBN 978-1-4398-5051-0.
- ^ Slocum, Jerry; Weisstein, Eric W. (1999). "15 - puzzle". MathWorld. Wolfram Research, Inc. Retrieved October 4, 2014.
- ^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bóna, 2004, p. 43
- ^ Combinatorics of Permutations, ISBN 1-58488-434-7, M. Bóna, 2004, p. 43ff
- ^ a b D. E. Knuth, The Art of Computer Programming, Vol 3, Sorting and Searching, Addison–Wesley (1973), p. 12. This book mentions the Lehmer code (without using that name) as a variant C1,...,Cn of inversion tables in exercise 5.1.1−7 (p. 19), together with two other variants.
- ^ H. A. Rothe, Sammlung combinatorisch-analytischer Abhandlungen 2 (Leipzig, 1800), 263−305. Cited in,[44] p. 14.
- ^ Fisher, R.A.; Yates, F. (1948) [1938]. Statistical tables for biological, agricultural and medical research (3rd ed.). London: Oliver & Boyd. pp. 26–27. OCLC 14222135.
- ^ a b Sedgewick, R (1977). "Permutation generation methods" (PDF). Computing Surveys 9: 137–164. doi:10.1145/356689.356692.
- ^ a b Knuth, D. E. (2005). "Generating All Tuples and Permutations". The Art of Computer Programming. 4, Fascicle 2. Addison-Wesley. pp. 1–26. ISBN 0-201-85393-0.
- ^ Heap, B. R. (1963). "Permutations by Interchanges" (PDF). The Computer Journal 6 (3): 293–4. doi:10.1093/comjnl/6.3.293.
- ^ Alexiou, A.; Psiha, P.; Vlamos (2011). "Combinatorial permutation based algorithm for representation of closed RNA secondary structures". Bioinformation 7 (2): 91–95. doi:10.6026/97320630007091. PMC 3174042. PMID 21938211.
- ^ http://h20331.www2.hp.com/Hpsub/downloads/50gProbability-Rearranging_items.pdf
- ^ 3GPP TS 36.212
- ^ Shlomi Dolev, Limor Lahiani, Yinnon Haviv, "Unique permutation hashing," Theoretical Computer Science Volume 475, 4 March 2013, Pages 59–65, http://www.sciencedirect.com/science/article/pii/S0304397513000133
References
- Bogart, Kenneth P. (1990), Introductory Combinatorics (2nd ed.), Harcourt Brace Jovanovich, ISBN 0-15-541576-X
- Bóna, Miklós (2004), Combinatorics of Permutations, Chapman Hall-CRC, ISBN 1-58488-434-7
- Brualdi, Richard A. (2010), Introductory Combinatorics (5th ed.), Prentice-Hall, ISBN 978-0-13-602040-0
- Cameron, Peter J. (1994), Combinatorics: Topics, Techniques, Algorithms, Cambridge University Press, ISBN 0-521-45761-0
- Carmichael, Robert D. (1956) [1937], Introduction to the theory of Groups of Finite Order, Dover, ISBN 0-486-60300-8
- Gerstein, Larry J. (1987), Discrete Mathematics and Algebraic Structures, W.H. Freeman and Co., ISBN 0-7167-1804-9
- Donald Knuth. The Art of Computer Programming, Volume 4: Generating All Tuples and Permutations, Fascicle 2, first printing. Addison–Wesley, 2005. ISBN 0-201-85393-0.
- Donald Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching, Second Edition. Addison–Wesley, 1998. ISBN 0-201-89685-0. Section 5.1: Combinatorial Properties of Permutations, pp. 11–72.
- Hall, Jr., Marshall (1959), The Theory of Groups, MacMillan
- Humphreys, J. F. (1996), A course in group theory, Oxford University Press, ISBN 978-0-19-853459-4
- Rotman, Joseph J. (2002), Advanced Modern Algebra, Prentice-Hall, ISBN 0-13-087868-5
- Stedman, Fabian (1677), Campanalogia, London The publisher is given as "W.S." who may have been William Smith, possibly acting as agent for the Society of College Youths, to which society the "Dedicatory" is addressed. In quotations the original long "S" has been replaced by a modern short "s".
External links
- Hazewinkel, Michiel, ed. (2001), "Permutation", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
| Wikimedia Commons has media related to Permutations. |
English Journal
- Unsupervised Learning of 3-D Local Features From Raw Voxels Based on a Novel Permutation Voxelization Strategy.
- Han Z, Liu Z, Han J, Vong CM, Bu S, Chen CLP.
- IEEE transactions on cybernetics. 2019 Feb;49(2)481-494.
- Effective 3-D local features are significant elements for 3-D shape analysis. Existing hand-crafted 3-D local descriptors are effective but usually involve intensive human intervention and prior knowledge, which burdens the subsequent processing procedures. An alternative resorts to the unsupervised
- PMID 29990288
- On what to permute in test-based approaches for variable importance measures in Random Forests.
- , N N, S S, S S, .
- Bioinformatics (Oxford, England). 2018 Dec;().
- In bioinformatics applications, it is currently customary to permute the outcome variable in order to produce inference on covariates to test novel methods or statistics whose distributions are poorly known. The seminal publication of Altmann et al. (2010) in Bioinformatics uses the same permutation
- PMID 30561510
- PERMutation Using Transposase Engineering (PERMUTE): A Simple Approach for Constructing Circularly Permuted Protein Libraries.
- Jones AM, Atkinson JT, Silberg JJ.
- Methods in molecular biology (Clifton, N.J.). 2017 ;1498()295-308.
- Rearrangements that alter the order of a protein's sequence are used in the lab to study protein folding, improve activity, and build molecular switches. One of the simplest ways to rearrange a protein sequence is through random circular permutation, where native protein termini are linked together
- PMID 27709583
Japanese Journal
- 一般化Radix Permute変換による無ひずみデータ圧縮(情報理論)
- 稲垣 和将,富澤 義宏,横尾 英俊
- 電子情報通信学会論文誌. A, 基礎・境界 J93-A(8), 535-543, 2010-08-01
- … 一般化Radix Permute変換は,筆者らがブロックソート・データ圧縮法のBWTの一般化として提案した記号列の可逆変換法である.本変換は,BWTのパラメータを伴う拡張になっている.本論文では,任意のパラメータ値に対する一般化Radix Permute変換を明らかにし,変換後のデータ圧縮に適したMove-to-Front変換の修正を提案する.これらの手法を組み合わせたデータ圧縮法を実装し,実際の圧縮実験を通じて,実際的な性能 …
- NAID 110007686271
- CQI Feedback Overhead Reduction for Multicarrier MIMO Transmission
- ZENG Erlin,ZHU Shihua,XU Ming
- IEICE transactions on communications 91(7), 2310-2320, 2008-07-01
- … The basic idea is to adaptively permute the CQI sequences of different MIMO streams according to one of the possible patterns before the DCT compression so that the amount of feedback bits is minimized. …
- NAID 10026831081
Related Pictures







