In statistics, identifiability is a property which a model must satisfy in order for precise inference to be possible. We say that the model is identifiable if it is theoretically possible to learn the true value of this model’s underlying parameter after obtaining an infinite number of observations from it. Mathematically, this is equivalent to saying that different values of the parameter must generate different probability distributions of the observable variables. Usually the model is identifiable only under certain technical restrictions, in which case the set of these requirements is called the identification conditions.
A model that fails to be identifiable is said to be non-identifiable or unidentifiable; two or more parametrizations are observationally equivalent. In some cases, even though a model is non-identifiable, it is still possible to learn the true values of a certain subset of the model parameters. In this case we say that the model is partially identifiable. In other cases it may be possible to learn the location of the true parameter up to a certain finite region of the parameter space, in which case the model is set identifiable.
Aside from strictly theoretical exploration of the model properties, Identifiability can be referred to in a wider scope when a model is tested with relation of experimental data sets. Usually these tests of Identifiability Analysis are applied when the model fitting of experimental data obtained and serve the detection of non-identifiable and sloppy parameters.[1]
Contents
- 1 Definition
- 2 Examples
- 2.1 Example 1
- 2.2 Example 2
- 2.3 Example 3
- 3 Software
- 4 See also
- 5 Notes
- 6 References
Definition
Let ℘ = {Pθ: θ∈Θ} be a statistical model where the parameter space Θ is either finite- or infinite-dimensional. We say that ℘ is identifiable if the mapping θ ↦ Pθ is one-to-one:[2]
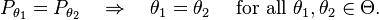
This definition means that distinct values of θ should correspond to distinct probability distributions: if θ1≠θ2, then also Pθ1≠Pθ2.[3] If the distributions are defined in terms of the probability density functions (pdfs), then two pdfs should be considered distinct only if they differ on a set of non-zero measure (for example two functions ƒ1(x)=10≤x<1 and ƒ2(x)=10≤x≤1 differ only at a single point x=1 — a set of measure zero — and thus cannot be considered as distinct pdfs).
Identifiability of the model in the sense of invertibility of the map θ ↦ Pθ is equivalent to being able to learn the model’s true parameter if the model can be observed indefinitely long. Indeed, if {Xt}⊆S is the sequence of observations from the model, then by the strong law of large numbers,
![\frac{1}{T} \sum_{t=1}^T \mathbf{1}_{\{X_t\in A\}} \ \xrightarrow{a.s.}\ \operatorname{Pr}[X_t\in A],](//upload.wikimedia.org/math/4/b/1/4b15230fdcd368b598ea11f6ceab6662.png)
for every measurable set A⊆S (here 1{…} is the indicator function). Thus with an infinite number of observations we will be able to find the true probability distribution P0 in the model, and since the identifiability condition above requires that the map θ ↦ Pθ be invertible, we will also be able to find the true value of the parameter which generated given distribution P0.
Examples
Example 1
Let ℘ be the normal location-scale family:

Then
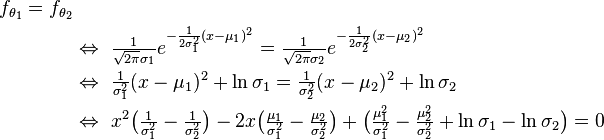
This expression is equal to zero for almost all x only when all its coefficients are equal to zero, which is only possible when |σ1| = |σ2| and μ1 = μ2. Since in the scale parameter σ is restricted to be greater than zero, we conclude that the model is identifiable: ƒθ1=ƒθ2 ⇔ θ1=θ2.
Example 2
Let ℘ be the standard linear regression model:
![y = \beta'x + \varepsilon, \quad \operatorname{E}[\,\varepsilon|x\,]=0](//upload.wikimedia.org/math/e/2/c/e2ca7aa3b1367203b73e28166acd4a59.png)
(where ′ denotes matrix transpose). Then the parameter β is identifiable if and only if the matrix E[xx′] is invertible. Thus, this is the identification condition in the model.
Example 3
Suppose ℘ is the classical errors-in-variables linear model:

where (ε,η,x*) are jointly normal independent random variables with zero expected value and unknown variances, and only the variables (x,y) are observed. Then this model is not identifiable,[4] only the product βσ²∗ is (where σ²∗ is the variance of the latent regressor x*). This is also an example of set identifiable model: although the exact value of β cannot be learned, we can guarantee that it must lie somewhere in the interval (βyx, 1÷βxy), where βyx is the coefficient in OLS regression of y on x, and βxy is the coefficient in OLS regression of x on y.[5]
If we abandon the normality assumption and require that x* were not normally distributed, retaining only the independence condition ε⊥η⊥x*, then the model becomes identifiable.[4]
Software
In the case of parameter estimation in partially observed dynamical systems, the profile likelihood can be also used for structural and practical identifiability analysis.[6] An implementation of the Profile Likelihood Approach is available in the MATLAB Toolbox PottersWheel.
See also
- Parameter identification problem
Notes
- ^ Raue, A.; Kreutz, C.; Maiwald, T.; Bachmann, J.; Schilling, M.; Klingmuller, U.; Timmer, J. (2009-08-01). "Structural and practical identifiability analysis of partially observed dynamical models by exploiting the profile likelihood". Bioinformatics 25 (15): 1923–1929. doi:10.1093/bioinformatics/btp358.
- ^ Lehmann & Casella 1998, Definition 1.5.2
- ^ van der Vaart 1998, p. 62
- ^ a b Reiersøl 1950
- ^ Casella & Berger 2001, p. 583
- ^ Raue, A; Kreutz, C; Maiwald, T; Bachmann, J; Schilling, M; Klingmüller, U; Timmer, J (2009), "Structural and practical identifiability analysis of partially observed dynamical models by exploiting the profile likelihood", Bioinformatics 25 (15): 1923–9, doi:10.1093/bioinformatics/btp358, PMID 19505944.
References
- Casella, George; Berger, Roger L. (2002), Statistical Inference (2nd ed.), ISBN 0-534-24312-6, LCCN 2001025794
- Hsiao, Cheng (1983), Identification, Handbook of Econometrics, Vol. 1, Ch.4, North-Holland Publishing Company
- Lehmann, E. L.; Casella, G. (1998), Theory of point estimation (2nd ed.), Springer, ISBN 0-387-98502-6
- Reiersøl, Olav (1950), "Identifiability of a linear relation between variables which are subject to error", Econometrica (The Econometric Society) 18 (4): 375–389, doi:10.2307/1907835, JSTOR 1907835
- van der Vaart, A.W. (1998), Asymptotic Statistics, Cambridge University Press, ISBN 978-0-521-49603-2
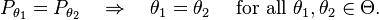
![\frac{1}{T} \sum_{t=1}^T \mathbf{1}_{\{X_t\in A\}} \ \xrightarrow{a.s.}\ \operatorname{Pr}[X_t\in A],](http://upload.wikimedia.org/math/4/b/1/4b15230fdcd368b598ea11f6ceab6662.png)

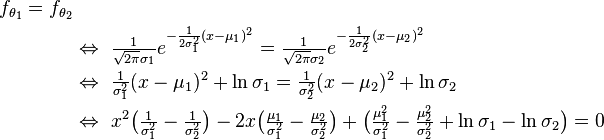
![y = \beta'x + \varepsilon, \quad \operatorname{E}[\,\varepsilon|x\,]=0](http://upload.wikimedia.org/math/e/2/c/e2ca7aa3b1367203b73e28166acd4a59.png)








