WordNet
- a precise rule (or set of rules) specifying how to solve some problem (同)algorithmic rule, algorithmic program
PrepTutorEJDIC
- アルゴリズム(最大公約数を求める互除法などの演算方式)
Wikipedia preview
出典(authority):フリー百科事典『ウィキペディア(Wikipedia)』「2016/04/19 20:21:28」(JST)
wiki en
For the supervised learning approach, see Statistical classification.
| Machine learning and data mining |
|---|
|
Problems
|
|
Supervised learning
(classification • regression)
|
|
Clustering
|
|
Dimensionality reduction
|
|
Structured prediction
|
|
Anomaly detection
|
|
Neural nets
|
|
Theory
|
|
Machine learning venues
|
|
|
The result of a cluster analysis shown as the coloring of the squares into three clusters.
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters). It is a main task of exploratory data mining, and a common technique for statistical data analysis, used in many fields, including machine learning, pattern recognition, image analysis, information retrieval, bioinformatics and data compression.
Cluster analysis itself is not one specific algorithm, but the general task to be solved. It can be achieved by various algorithms that differ significantly in their notion of what constitutes a cluster and how to efficiently find them. Popular notions of clusters include groups with small distances among the cluster members, dense areas of the data space, intervals or particular statistical distributions. Clustering can therefore be formulated as a multi-objective optimization problem. The appropriate clustering algorithm and parameter settings (including values such as the distance function to use, a density threshold or the number of expected clusters) depend on the individual data set and intended use of the results. Cluster analysis as such is not an automatic task, but an iterative process of knowledge discovery or interactive multi-objective optimization that involves trial and failure. It is often necessary to modify data preprocessing and model parameters until the result achieves the desired properties.
Besides the term clustering, there are a number of terms with similar meanings, including automatic classification, numerical taxonomy, botryology (from Greek βότρυς "grape") and typological analysis. The subtle differences are often in the usage of the results: while in data mining, the resulting groups are the matter of interest, in automatic classification the resulting discriminative power is of interest. This often leads to misunderstandings between researchers coming from the fields of data mining and machine learning, since they use the same terms and often the same algorithms, but have different goals.
Cluster analysis was originated in anthropology by Driver and Kroeber in 1932 and introduced to psychology by Zubin in 1938 and Robert Tryon in 1939[1][2] and famously used by Cattell beginning in 1943[3] for trait theory classification in personality psychology.
Contents
- 1 Definition
- 2 Algorithms
- 2.1 Connectivity based clustering (hierarchical clustering)
- 2.2 Centroid-based clustering
- 2.3 Distribution-based clustering
- 2.4 Density-based clustering
- 2.5 Recent developments
- 2.6 Other methods
- 3 Evaluation and assessment
- 3.1 Internal evaluation
- 3.2 External evaluation
- 4 Applications
- 5 See also
- 5.1 Specialized types of cluster analysis
- 5.2 Techniques used in cluster analysis
- 5.3 Data projection and preprocessing
- 5.4 Other
- 6 References
- 7 External links
Definition
The notion of a "cluster" cannot be precisely defined, which is one of the reasons why there are so many clustering algorithms.[4] There is a common denominator: a group of data objects. However, different researchers employ different cluster models, and for each of these cluster models again different algorithms can be given. The notion of a cluster, as found by different algorithms, varies significantly in its properties. Understanding these "cluster models" is key to understanding the differences between the various algorithms. Typical cluster models include:
- Connectivity models: for example, hierarchical clustering builds models based on distance connectivity.
- Centroid models: for example, the k-means algorithm represents each cluster by a single mean vector.
- Distribution models: clusters are modeled using statistical distributions, such as multivariate normal distributions used by the Expectation-maximization algorithm.
- Density models: for example, DBSCAN and OPTICS defines clusters as connected dense regions in the data space.
- Subspace models: in Biclustering (also known as Co-clustering or two-mode-clustering), clusters are modeled with both cluster members and relevant attributes.
- Group models: some algorithms do not provide a refined model for their results and just provide the grouping information.
- Graph-based models: a clique, that is, a subset of nodes in a graph such that every two nodes in the subset are connected by an edge can be considered as a prototypical form of cluster. Relaxations of the complete connectivity requirement (a fraction of the edges can be missing) are known as quasi-cliques, as in the HCS clustering algorithm.
A "clustering" is essentially a set of such clusters, usually containing all objects in the data set. Additionally, it may specify the relationship of the clusters to each other, for example, a hierarchy of clusters embedded in each other. Clusterings can be roughly distinguished as:
- hard clustering: each object belongs to a cluster or not
- soft clustering (also: fuzzy clustering): each object belongs to each cluster to a certain degree (for example, a likelihood of belonging to the cluster)
There are also finer distinctions possible, for example:
- strict partitioning clustering: here each object belongs to exactly one cluster
- strict partitioning clustering with outliers: objects can also belong to no cluster, and are considered outliers.
- overlapping clustering (also: alternative clustering, multi-view clustering): while usually a hard clustering, objects may belong to more than one cluster.
- hierarchical clustering: objects that belong to a child cluster also belong to the parent cluster
- subspace clustering: while an overlapping clustering, within a uniquely defined subspace, clusters are not expected to overlap.
Algorithms
Main category: Data clustering algorithms
Clustering algorithms can be categorized based on their cluster model, as listed above. The following overview will only list the most prominent examples of clustering algorithms, as there are possibly over 100 published clustering algorithms. Not all provide models for their clusters and can thus not easily be categorized. An overview of algorithms explained in Wikipedia can be found in the list of statistics algorithms.
There is no objectively "correct" clustering algorithm, but as it was noted, "clustering is in the eye of the beholder."[4] The most appropriate clustering algorithm for a particular problem often needs to be chosen experimentally, unless there is a mathematical reason to prefer one cluster model over another. It should be noted that an algorithm that is designed for one kind of model has no chance on a data set that contains a radically different kind of model.[4] For example, k-means cannot find non-convex clusters.[4]
Connectivity based clustering (hierarchical clustering)
Main article: Hierarchical clustering
Connectivity based clustering, also known as hierarchical clustering, is based on the core idea of objects being more related to nearby objects than to objects farther away. These algorithms connect "objects" to form "clusters" based on their distance. A cluster can be described largely by the maximum distance needed to connect parts of the cluster. At different distances, different clusters will form, which can be represented using a dendrogram, which explains where the common name "hierarchical clustering" comes from: these algorithms do not provide a single partitioning of the data set, but instead provide an extensive hierarchy of clusters that merge with each other at certain distances. In a dendrogram, the y-axis marks the distance at which the clusters merge, while the objects are placed along the x-axis such that the clusters don't mix.
Connectivity based clustering is a whole family of methods that differ by the way distances are computed. Apart from the usual choice of distance functions, the user also needs to decide on the linkage criterion (since a cluster consists of multiple objects, there are multiple candidates to compute the distance to) to use. Popular choices are known as single-linkage clustering (the minimum of object distances), complete linkage clustering (the maximum of object distances) or UPGMA ("Unweighted Pair Group Method with Arithmetic Mean", also known as average linkage clustering). Furthermore, hierarchical clustering can be agglomerative (starting with single elements and aggregating them into clusters) or divisive (starting with the complete data set and dividing it into partitions).
These methods will not produce a unique partitioning of the data set, but a hierarchy from which the user still needs to choose appropriate clusters. They are not very robust towards outliers, which will either show up as additional clusters or even cause other clusters to merge (known as "chaining phenomenon", in particular with single-linkage clustering). In the general case, the complexity is for agglomerative clustering and for divisive clustering,[5] which makes them too slow for large data sets. For some special cases, optimal efficient methods (of complexity ) are known: SLINK[6] for single-linkage and CLINK[7] for complete-linkage clustering. In the data mining community these methods are recognized as a theoretical foundation of cluster analysis, but often considered obsolete[citation needed]. They did however provide inspiration for many later methods such as density based clustering.
- Linkage clustering examples
-
Single-linkage on Gaussian data. At 35 clusters, the biggest cluster starts fragmenting into smaller parts, while before it was still connected to the second largest due to the single-link effect.
-
Single-linkage on density-based clusters. 20 clusters extracted, most of which contain single elements, since linkage clustering does not have a notion of "noise".
Centroid-based clustering
Main article: k-means clustering
In centroid-based clustering, clusters are represented by a central vector, which may not necessarily be a member of the data set. When the number of clusters is fixed to k, k-means clustering gives a formal definition as an optimization problem: find the cluster centers and assign the objects to the nearest cluster center, such that the squared distances from the cluster are minimized.
The optimization problem itself is known to be NP-hard, and thus the common approach is to search only for approximate solutions. A particularly well known approximative method is Lloyd's algorithm,[8] often actually referred to as "k-means algorithm". It does however only find a local optimum, and is commonly run multiple times with different random initializations. Variations of k-means often include such optimizations as choosing the best of multiple runs, but also restricting the centroids to members of the data set (k-medoids), choosing medians (k-medians clustering), choosing the initial centers less randomly (K-means++) or allowing a fuzzy cluster assignment (Fuzzy c-means).
Most k-means-type algorithms require the number of clusters - - to be specified in advance, which is considered to be one of the biggest drawbacks of these algorithms. Furthermore, the algorithms prefer clusters of approximately similar size, as they will always assign an object to the nearest centroid. This often leads to incorrectly cut borders in between of clusters (which is not surprising, as the algorithm optimized cluster centers, not cluster borders).
K-means has a number of interesting theoretical properties. First, it partitions the data space into a structure known as a Voronoi diagram. Second, it is conceptually close to nearest neighbor classification, and as such is popular in machine learning. Third, it can be seen as a variation of model based classification, and Lloyd's algorithm as a variation of the Expectation-maximization algorithm for this model discussed below.
- k-Means clustering examples
-
K-means separates data into Voronoi-cells, which assumes equal-sized clusters (not adequate here)
-
K-means cannot represent density-based clusters
Distribution-based clustering
The clustering model most closely related to statistics is based on distribution models. Clusters can then easily be defined as objects belonging most likely to the same distribution. A convenient property of this approach is that this closely resembles the way artificial data sets are generated: by sampling random objects from a distribution.
While the theoretical foundation of these methods is excellent, they suffer from one key problem known as overfitting, unless constraints are put on the model complexity. A more complex model will usually be able to explain the data better, which makes choosing the appropriate model complexity inherently difficult.
One prominent method is known as Gaussian mixture models (using the expectation-maximization algorithm). Here, the data set is usually modelled with a fixed (to avoid overfitting) number of Gaussian distributions that are initialized randomly and whose parameters are iteratively optimized to fit better to the data set. This will converge to a local optimum, so multiple runs may produce different results. In order to obtain a hard clustering, objects are often then assigned to the Gaussian distribution they most likely belong to; for soft clusterings, this is not necessary.
Distribution-based clustering produces complex models for clusters that can capture correlation and dependence between attributes. However, these algorithms put an extra burden on the user: for many real data sets, there may be no concisely defined mathematical model (e.g. assuming Gaussian distributions is a rather strong assumption on the data).
- Expectation-Maximization (EM) clustering examples
-
On Gaussian-distributed data, EM works well, since it uses Gaussians for modelling clusters
-
Density-based clusters cannot be modeled using Gaussian distributions
Density-based clustering
In density-based clustering,[9] clusters are defined as areas of higher density than the remainder of the data set. Objects in these sparse areas - that are required to separate clusters - are usually considered to be noise and border points.
The most popular[10] density based clustering method is DBSCAN.[11] In contrast to many newer methods, it features a well-defined cluster model called "density-reachability". Similar to linkage based clustering, it is based on connecting points within certain distance thresholds. However, it only connects points that satisfy a density criterion, in the original variant defined as a minimum number of other objects within this radius. A cluster consists of all density-connected objects (which can form a cluster of an arbitrary shape, in contrast to many other methods) plus all objects that are within these objects' range. Another interesting property of DBSCAN is that its complexity is fairly low - it requires a linear number of range queries on the database - and that it will discover essentially the same results (it is deterministic for core and noise points, but not for border points) in each run, therefore there is no need to run it multiple times. OPTICS[12] is a generalization of DBSCAN that removes the need to choose an appropriate value for the range parameter , and produces a hierarchical result related to that of linkage clustering. DeLi-Clu,[13] Density-Link-Clustering combines ideas from single-linkage clustering and OPTICS, eliminating the parameter entirely and offering performance improvements over OPTICS by using an R-tree index.
The key drawback of DBSCAN and OPTICS is that they expect some kind of density drop to detect cluster borders. Moreover, they cannot detect intrinsic cluster structures which are prevalent in the majority of real life data. A variation of DBSCAN, EnDBSCAN,[14] efficiently detects such kinds of structures. On data sets with, for example, overlapping Gaussian distributions - a common use case in artificial data - the cluster borders produced by these algorithms will often look arbitrary, because the cluster density decreases continuously. On a data set consisting of mixtures of Gaussians, these algorithms are nearly always outperformed by methods such as EM clustering that are able to precisely model this kind of data.
Mean-shift is a clustering approach where each object is moved to the densest area in its vicinity, based on kernel density estimation. Eventually, objects converge to local maxima of density. Similar to k-means clustering, these "density attractors" can serve as representatives for the data set, but mean-shift can detect arbitrary-shaped clusters similar to DBSCAN. Due to the expensive iterative procedure and density estimation, mean-shift is usually slower than DBSCAN or k-Means.
- Density-based clustering examples
-
Density-based clustering with DBSCAN.
-
DBSCAN assumes clusters of similar density, and may have problems separating nearby clusters
-
OPTICS is a DBSCAN variant that handles different densities much better
Recent developments
In recent years considerable effort has been put into improving the performance of existing algorithms.[15][16] Among them are CLARANS (Ng and Han, 1994),[17] and BIRCH (Zhang et al., 1996).[18] With the recent need to process larger and larger data sets (also known as big data), the willingness to trade semantic meaning of the generated clusters for performance has been increasing. This led to the development of pre-clustering methods such as canopy clustering, which can process huge data sets efficiently, but the resulting "clusters" are merely a rough pre-partitioning of the data set to then analyze the partitions with existing slower methods such as k-means clustering. Various other approaches to clustering have been tried such as seed based clustering.[19]
For high-dimensional data, many of the existing methods fail due to the curse of dimensionality, which renders particular distance functions problematic in high-dimensional spaces. This led to new clustering algorithms for high-dimensional data that focus on subspace clustering (where only some attributes are used, and cluster models include the relevant attributes for the cluster) and correlation clustering that also looks for arbitrary rotated ("correlated") subspace clusters that can be modeled by giving a correlation of their attributes. Examples for such clustering algorithms are CLIQUE[20] and SUBCLU.[21]
Ideas from density-based clustering methods (in particular the DBSCAN/OPTICS family of algorithms) have been adopted to subspace clustering (HiSC,[22] hierarchical subspace clustering and DiSH[23]) and correlation clustering (HiCO,[24] hierarchical correlation clustering, 4C[25] using "correlation connectivity" and ERiC[26] exploring hierarchical density-based correlation clusters).
Several different clustering systems based on mutual information have been proposed. One is Marina Meilă's variation of information metric;[27] another provides hierarchical clustering.[28] Using genetic algorithms, a wide range of different fit-functions can be optimized, including mutual information.[29] Also message passing algorithms, a recent development in Computer Science and Statistical Physics, has led to the creation of new types of clustering algorithms.[30]
Other methods
- Basic sequential algorithmic scheme (BSAS)
Evaluation and assessment
Evaluation of clustering results sometimes is referred to as cluster validation.
There have been several suggestions for a measure of similarity between two clusterings. Such a measure can be used to compare how well different data clustering algorithms perform on a set of data. These measures are usually tied to the type of criterion being considered in assessing the quality of a clustering method.
Internal evaluation
See also: Determining the number of clusters in a data set
When a clustering result is evaluated based on the data that was clustered itself, this is called internal evaluation. These methods usually assign the best score to the algorithm that produces clusters with high similarity within a cluster and low similarity between clusters. One drawback of using internal criteria in cluster evaluation is that high scores on an internal measure do not necessarily result in effective information retrieval applications.[31] Additionally, this evaluation is biased towards algorithms that use the same cluster model. For example, k-Means clustering naturally optimizes object distances, and a distance-based internal criterion will likely overrate the resulting clustering.
Therefore, the internal evaluation measures are best suited to get some insight into situations where one algorithm performs better than another, but this shall not imply that one algorithm produces more valid results than another.[4] Validity as measured by such an index depends on the claim that this kind of structure exists in the data set. An algorithm designed for some kind of models has no chance if the data set contains a radically different set of models, or if the evaluation measures a radically different criterion.[4] For example, k-means clustering can only find convex clusters, and many evaluation indexes assume convex clusters. On a data set with non-convex clusters neither the use of k-means, nor of an evaluation criterion that assumes convexity, is sound.
The following methods can be used to assess the quality of clustering algorithms based on internal criterion:
- Davies–Bouldin index
- The Davies–Bouldin index can be calculated by the following formula:

- where n is the number of clusters, is the centroid of cluster , is the average distance of all elements in cluster to centroid , and is the distance between centroids and . Since algorithms that produce clusters with low intra-cluster distances (high intra-cluster similarity) and high inter-cluster distances (low inter-cluster similarity) will have a low Davies–Bouldin index, the clustering algorithm that produces a collection of clusters with the smallest Davies–Bouldin index is considered the best algorithm based on this criterion.

- Dunn index
- The Dunn index aims to identify dense and well-separated clusters. It is defined as the ratio between the minimal inter-cluster distance to maximal intra-cluster distance. For each cluster partition, the Dunn index can be calculated by the following formula:[32]
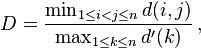
- where d(i,j) represents the distance between clusters i and j, and d '(k) measures the intra-cluster distance of cluster k. The inter-cluster distance d(i,j) between two clusters may be any number of distance measures, such as the distance between the centroids of the clusters. Similarly, the intra-cluster distance d '(k) may be measured in a variety ways, such as the maximal distance between any pair of elements in cluster k. Since internal criterion seek clusters with high intra-cluster similarity and low inter-cluster similarity, algorithms that produce clusters with high Dunn index are more desirable.
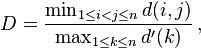
- Silhouette coefficient
- The silhouette coefficient contrasts the average distance to elements in the same cluster with the average distance to elements in other clusters. Objects with a high silhouette value are considered well clustered, objects with a low value may be outliers. This index works well with k-means clustering, and is also used to determine the optimal number of clusters.
External evaluation
In external evaluation, clustering results are evaluated based on data that was not used for clustering, such as known class labels and external benchmarks. Such benchmarks consist of a set of pre-classified items, and these sets are often created by (expert) humans. Thus, the benchmark sets can be thought of as a gold standard for evaluation. These types of evaluation methods measure how close the clustering is to the predetermined benchmark classes. However, it has recently been discussed whether this is adequate for real data, or only on synthetic data sets with a factual ground truth, since classes can contain internal structure, the attributes present may not allow separation of clusters or the classes may contain anomalies.[33] Additionally, from a knowledge discovery point of view, the reproduction of known knowledge may not necessarily be the intended result.[33] In the special scenario of Constrained clustering, where meta information (such as class labels) is used already in the clustering process, the hold-out of information for evaluation purposes is non-trivial.[34]
A number of measures are adapted from variants used to evaluate classification tasks. In place of counting the number of times a class was correctly assigned to a single data point (known as true positives), such pair counting metrics assess whether each pair of data points that is truly in the same cluster is predicted to be in the same cluster.
Some of the measures of quality of a cluster algorithm using external criterion include:
- Rand measure (William M. Rand 1971)[35]
- The Rand index computes how similar the clusters (returned by the clustering algorithm) are to the benchmark classifications. One can also view the Rand index as a measure of the percentage of correct decisions made by the algorithm. It can be computed using the following formula:
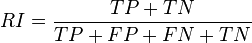
- where is the number of true positives, is the number of true negatives, is the number of false positives, and is the number of false negatives. One issue with the Rand index is that false positives and false negatives are equally weighted. This may be an undesirable characteristic for some clustering applications. The F-measure addresses this concern, as does the chance-corrected adjusted Rand index.
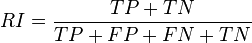
- F-measure
- The F-measure can be used to balance the contribution of false negatives by weighting recall through a parameter . Let precision and recall be defined as follows:
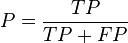
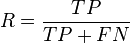
- where is the precision rate and is the recall rate. We can calculate the F-measure by using the following formula:[31]
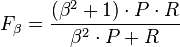
- Notice that when , . In other words, recall has no impact on the F-measure when , and increasing allocates an increasing amount of weight to recall in the final F-measure.
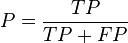
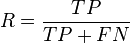
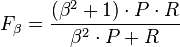
- Jaccard index
- The Jaccard index is used to quantify the similarity between two datasets. The Jaccard index takes on a value between 0 and 1. An index of 1 means that the two dataset are identical, and an index of 0 indicates that the datasets have no common elements. The Jaccard index is defined by the following formula:

- This is simply the number of unique elements common to both sets divided by the total number of unique elements in both sets.

- Fowlkes–Mallows index (E. B. Fowlkes & C. L. Mallows 1983)[36]
- The Fowlkes-Mallows index computes the similarity between the clusters returned by the clustering algorithm and the benchmark classifications. The higher the value of the Fowlkes-Mallows index the more similar the clusters and the benchmark classifications are. It can be computed using the following formula:
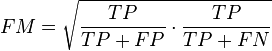
- where is the number of true positives, is the number of false positives, and is the number of false negatives. The index is the geometric mean of the precision and recall and , while the F-measure is their harmonic mean.[37] Moreover, precision and recall are also known as Wallace's indices and .[38]
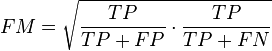
- The Mutual Information is an information theoretic measure of how much information is shared between a clustering and a ground-truth classification that can detect a non-linear similarity between two clusterings. Adjusted mutual information is the corrected-for-chance variant of this that has a reduced bias for varying cluster numbers.
- Confusion matrix
- A confusion matrix can be used to quickly visualize the results of a classification (or clustering) algorithm. It shows how different a cluster is from the gold standard cluster.
Applications
- Biology, computational biology and bioinformatics
-
- Plant and animal ecology
- cluster analysis is used to describe and to make spatial and temporal comparisons of communities (assemblages) of organisms in heterogeneous environments; it is also used in plant systematics to generate artificial phylogenies or clusters of organisms (individuals) at the species, genus or higher level that share a number of attributes
- Transcriptomics
- clustering is used to build groups of genes with related expression patterns (also known as coexpressed genes) as in HCS clustering algorithm . Often such groups contain functionally related proteins, such as enzymes for a specific pathway, or genes that are co-regulated. High throughput experiments using expressed sequence tags (ESTs) or DNA microarrays can be a powerful tool for genome annotation, a general aspect of genomics.
- Sequence analysis
- clustering is used to group homologous sequences into gene families. This is a very important concept in bioinformatics, and evolutionary biology in general. See evolution by gene duplication.
- High-throughput genotyping platforms
- clustering algorithms are used to automatically assign genotypes.
- Human genetic clustering
- The similarity of genetic data is used in clustering to infer population structures.
- Medicine
-
- Medical imaging
- On PET scans, cluster analysis can be used to differentiate between different types of tissue and blood in a three-dimensional image. In this application, actual position does not matter, but the voxel intensity is considered as a vector, with a dimension for each image that was taken over time. This technique allows, for example, accurate measurement of the rate a radioactive tracer is delivered to the area of interest, without a separate sampling of arterial blood, an intrusive technique that is most common today.
- Analysis of antimicrobial activity
- Cluster analysis can be used to analyse patterns of antibiotic resistance, to classify antimicrobial compounds according to their mechanism of action, to classify antibiotics according to their antibacterial activity.
- IMRT segmentation
- Clustering can be used to divide a fluence map into distinct regions for conversion into deliverable fields in MLC-based Radiation Therapy.
- Business and marketing
-
- Market research
- Cluster analysis is widely used in market research when working with multivariate data from surveys and test panels. Market researchers use cluster analysis to partition the general population of consumers into market segments and to better understand the relationships between different groups of consumers/potential customers, and for use in market segmentation, Product positioning, New product development and Selecting test markets.
- Grouping of shopping items
- Clustering can be used to group all the shopping items available on the web into a set of unique products. For example, all the items on eBay can be grouped into unique products. (eBay doesn't have the concept of a SKU)
- World wide web
-
- Social network analysis
- In the study of social networks, clustering may be used to recognize communities within large groups of people.
- Search result grouping
- In the process of intelligent grouping of the files and websites, clustering may be used to create a more relevant set of search results compared to normal search engines like Google. There are currently a number of web based clustering tools such as Clusty.
- Slippy map optimization
- Flickr's map of photos and other map sites use clustering to reduce the number of markers on a map. This makes it both faster and reduces the amount of visual clutter.
- Computer science
-
- Software evolution
- Clustering is useful in software evolution as it helps to reduce legacy properties in code by reforming functionality that has become dispersed. It is a form of restructuring and hence is a way of direct preventative maintenance.
- Image segmentation
- Clustering can be used to divide a digital image into distinct regions for border detection or object recognition.[39]
- Evolutionary algorithms
- Clustering may be used to identify different niches within the population of an evolutionary algorithm so that reproductive opportunity can be distributed more evenly amongst the evolving species or subspecies.
- Recommender systems
- Recommender systems are designed to recommend new items based on a user's tastes. They sometimes use clustering algorithms to predict a user's preferences based on the preferences of other users in the user's cluster.
- Markov chain Monte Carlo methods
- Clustering is often utilized to locate and characterize extrema in the target distribution.
- Anomaly detection
- Anomalies/outliers are typically - be it explicitly or implicitly - defined with respect to clustering structure in data.
- Social science
-
- Crime analysis
- Cluster analysis can be used to identify areas where there are greater incidences of particular types of crime. By identifying these distinct areas or "hot spots" where a similar crime has happened over a period of time, it is possible to manage law enforcement resources more effectively.
- Educational data mining
- Cluster analysis is for example used to identify groups of schools or students with similar properties.
- Typologies
- From poll data, projects such as those undertaken by the Pew Research Center use cluster analysis to discern typologies of opinions, habits, and demographics that may be useful in politics and marketing.
- Others
-
- Field robotics
- Clustering algorithms are used for robotic situational awareness to track objects and detect outliers in sensor data.[40]
- Mathematical chemistry
- To find structural similarity, etc., for example, 3000 chemical compounds were clustered in the space of 90 topological indices.[41]
- Climatology
- To find weather regimes or preferred sea level pressure atmospheric patterns.[42]
- Petroleum geology
- Cluster analysis is used to reconstruct missing bottom hole core data or missing log curves in order to evaluate reservoir properties.
- Physical geography
- The clustering of chemical properties in different sample locations.
See also
| Wikimedia Commons has media related to Cluster analysis. |
Specialized types of cluster analysis
- Balanced clustering
- Clustering high-dimensional data
- Conceptual clustering
- Consensus clustering
- Constrained clustering
- Data stream clustering
- HCS clustering
- Sequence clustering
- Spectral clustering
Techniques used in cluster analysis
- Artificial neural network (ANN)
- Nearest neighbor search
- Neighbourhood components analysis
- Latent class analysis
Data projection and preprocessing
- Dimension reduction
- Principal component analysis
- Multidimensional scaling
Other
- Cluster-weighted modeling
- Curse of dimensionality
- Determining the number of clusters in a data set
- Parallel coordinates
- Structured data analysis
References
- ^ Bailey, Ken (1994). "Numerical Taxonomy and Cluster Analysis". Typologies and Taxonomies. p. 34. ISBN 9780803952591.
- ^ Tryon, Robert C. (1939). Cluster Analysis: Correlation Profile and Orthometric (factor) Analysis for the Isolation of Unities in Mind and Personality. Edwards Brothers.
- ^ Cattell, R. B. (1943). "The description of personality: Basic traits resolved into clusters". Journal of Abnormal and Social Psychology 38: 476–506. doi:10.1037/h0054116.
- ^ a b c d e f Estivill-Castro, Vladimir (20 June 2002). "Why so many clustering algorithms — A Position Paper". ACM SIGKDD Explorations Newsletter 4 (1): 65–75. doi:10.1145/568574.568575.
- ^ Everitt, Brian (2011). Cluster analysis. Chichester, West Sussex, U.K: Wiley. ISBN 9780470749913.
- ^ Sibson, R. (1973). "SLINK: an optimally efficient algorithm for the single-link cluster method" (PDF). The Computer Journal (British Computer Society) 16 (1): 30–34. doi:10.1093/comjnl/16.1.30.
- ^ Defays, D. (1977). "An efficient algorithm for a complete link method". The Computer Journal (British Computer Society) 20 (4): 364–366. doi:10.1093/comjnl/20.4.364.
- ^ Lloyd, S. (1982). "Least squares quantization in PCM". IEEE Transactions on Information Theory 28 (2): 129–137. doi:10.1109/TIT.1982.1056489.
- ^ Kriegel, Hans-Peter; Kröger, Peer; Sander, Jörg; Zimek, Arthur (2011). "Density-based Clustering". WIREs Data Mining and Knowledge Discovery 1 (3): 231–240. doi:10.1002/widm.30.
- ^ Microsoft academic search: most cited data mining articles: DBSCAN is on rank 24, when accessed on: 4/18/2010
- ^ Ester, Martin; Kriegel, Hans-Peter; Sander, Jörg; Xu, Xiaowei (1996). "A density-based algorithm for discovering clusters in large spatial databases with noise". In Simoudis, Evangelos; Han, Jiawei; Fayyad, Usama M. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). AAAI Press. pp. 226–231. ISBN 1-57735-004-9. CiteSeerX: 10
.1 .1 .71 .1980. - ^ Ankerst, Mihael; Breunig, Markus M.; Kriegel, Hans-Peter; Sander, Jörg (1999). "OPTICS: Ordering Points To Identify the Clustering Structure". ACM SIGMOD international conference on Management of data. ACM Press. pp. 49–60. CiteSeerX: 10
.1 .1 .129 .6542. - ^ Achtert, E.; Böhm, C.; Kröger, P. (2006). "DeLi-Clu: Boosting Robustness, Completeness, Usability, and Efficiency of Hierarchical Clustering by a Closest Pair Ranking". LNCS: Advances in Knowledge Discovery and Data Mining. Lecture Notes in Computer Science 3918: 119–128. doi:10.1007/11731139_16. ISBN 978-3-540-33206-0.
- ^ Roy, S.; Bhattacharyya, D. K. (2005). "An Approach to find Embedded Clusters Using Density Based Techniques". LNCS Vol.3816. Springer Verlag. pp. 523–535.
- ^ Sculley, D. (2010). Web-scale k-means clustering. Proc. 19th WWW.
- ^ Huang, Z. (1998). "Extensions to the k-means algorithm for clustering large data sets with categorical values". Data Mining and Knowledge Discovery 2: 283–304.
- ^ R. Ng and J. Han. "Efficient and effective clustering method for spatial data mining". In: Proceedings of the 20th VLDB Conference, pages 144-155, Santiago, Chile, 1994.
- ^ Tian Zhang, Raghu Ramakrishnan, Miron Livny. "An Efficient Data Clustering Method for Very Large Databases." In: Proc. Int'l Conf. on Management of Data, ACM SIGMOD, pp. 103–114.
- ^ Can, F.; Ozkarahan, E. A. (1990). "Concepts and effectiveness of the cover-coefficient-based clustering methodology for text databases". ACM Transactions on Database Systems 15 (4): 483. doi:10.1145/99935.99938.
- ^ Agrawal, R.; Gehrke, J.; Gunopulos, D.; Raghavan, P. (2005). "Automatic Subspace Clustering of High Dimensional Data". Data Mining and Knowledge Discovery 11: 5. doi:10.1007/s10618-005-1396-1.
- ^ Karin Kailing, Hans-Peter Kriegel and Peer Kröger. Density-Connected Subspace Clustering for High-Dimensional Data. In: Proc. SIAM Int. Conf. on Data Mining (SDM'04), pp. 246-257, 2004.
- ^ Achtert, E.; Böhm, C.; Kriegel, H. P.; Kröger, P.; Müller-Gorman, I.; Zimek, A. (2006). "Finding Hierarchies of Subspace Clusters". LNCS: Knowledge Discovery in Databases: PKDD 2006. Lecture Notes in Computer Science 4213: 446–453. doi:10.1007/11871637_42. ISBN 978-3-540-45374-1.
- ^ Achtert, E.; Böhm, C.; Kriegel, H. P.; Kröger, P.; Müller-Gorman, I.; Zimek, A. (2007). "Detection and Visualization of Subspace Cluster Hierarchies". LNCS: Advances in Databases: Concepts, Systems and Applications. Lecture Notes in Computer Science 4443: 152–163. doi:10.1007/978-3-540-71703-4_15. ISBN 978-3-540-71702-7.
- ^ Achtert, E.; Böhm, C.; Kröger, P.; Zimek, A. (2006). "Mining Hierarchies of Correlation Clusters". Proc. 18th International Conference on Scientific and Statistical Database Management (SSDBM): 119–128. doi:10.1109/SSDBM.2006.35. ISBN 0-7695-2590-3.
- ^ Böhm, C.; Kailing, K.; Kröger, P.; Zimek, A. (2004). "Computing Clusters of Correlation Connected objects". Proceedings of the 2004 ACM SIGMOD international conference on Management of data - SIGMOD '04. p. 455. doi:10.1145/1007568.1007620. ISBN 1581138598.
- ^ Achtert, E.; Bohm, C.; Kriegel, H. P.; Kröger, P.; Zimek, A. (2007). "On Exploring Complex Relationships of Correlation Clusters". 19th International Conference on Scientific and Statistical Database Management (SSDBM 2007). p. 7. doi:10.1109/SSDBM.2007.21. ISBN 0-7695-2868-6.
- ^ Meilă, Marina (2003). "Comparing Clusterings by the Variation of Information". Learning Theory and Kernel Machines. Lecture Notes in Computer Science 2777: 173–187. doi:10.1007/978-3-540-45167-9_14. ISBN 978-3-540-40720-1.
- ^ Kraskov, Alexander; Stögbauer, Harald; Andrzejak, Ralph G.; Grassberger, Peter (1 December 2003) [28 November 2003]. "Hierarchical Clustering Based on Mutual Information". arXiv:q-bio/0311039.
- ^ Auffarth, B. (July 18–23, 2010). "Clustering by a Genetic Algorithm with Biased Mutation Operator". WCCI CEC (IEEE). CiteSeerX: 10
.1 .1 .170 .869. - ^ Frey, B. J.; Dueck, D. (2007). "Clustering by Passing Messages Between Data Points". Science 315 (5814): 972–976. doi:10.1126/science.1136800. PMID 17218491.
- ^ a b Manning, Christopher D.; Raghavan, Prabhakar; Schütze, Hinrich. Introduction to Information Retrieval. Cambridge University Press. ISBN 978-0-521-86571-5.
- ^ Dunn, J. (1974). "Well separated clusters and optimal fuzzy partitions". Journal of Cybernetics 4: 95–104. doi:10.1080/01969727408546059.
- ^ a b Färber, Ines; Günnemann, Stephan; Kriegel, Hans-Peter; Kröger, Peer; Müller, Emmanuel; Schubert, Erich; Seidl, Thomas; Zimek, Arthur (2010). "On Using Class-Labels in Evaluation of Clusterings" (PDF). In Fern, Xiaoli Z.; Davidson, Ian; Dy, Jennifer. MultiClust: Discovering, Summarizing, and Using Multiple Clusterings. ACM SIGKDD.
- ^ Pourrajabi, M.; Moulavi, D.; Campello, R. J. G. B.; Zimek, A.; Sander, J.; Goebel, R. (2014). "Model Selection for Semi-Supervised Clustering". Proceedings of the 17th International Conference on Extending Database Technology (EDBT),. pp. 331–342. doi:10.5441/002/edbt.2014.31.
- ^ Rand, W. M. (1971). "Objective criteria for the evaluation of clustering methods". Journal of the American Statistical Association (American Statistical Association) 66 (336): 846–850. doi:10.2307/2284239. JSTOR 2284239.
- ^ E. B. Fowlkes & C. L. Mallows (1983), "A Method for Comparing Two Hierarchical Clusterings", Journal of the American Statistical Association 78, 553–569.
- ^ L. Hubert et P. Arabie. Comparing partitions. J. of Classification, 2(1), 1985.
- ^ D. L. Wallace. Comment. Journal of the American Statistical Association, 78 :569– 579, 1983.
- ^ Bewley, A., & Upcroft, B. (2013). Advantages of Exploiting Projection Structure for Segmenting Dense 3D Point Clouds. In Australian Conference on Robotics and Automation [1]
- ^ Bewley, A.; et al. "Real-time volume estimation of a dragline payload". IEEE International Conference on Robotics and Automation 2011: 1571–1576.
- ^ Basak, S.C.; Magnuson, V.R.; Niemi, C.J.; Regal, R.R. "Determining Structural Similarity of Chemicals Using Graph Theoretic Indices". Discr. Appl. Math., 19 1988: 17–44.
- ^ Huth, R.; et al. (2008). "Classifications of Atmospheric Circulation Patterns: Recent Advances and Applications". Ann. N.Y. Acad. Sci. 1146: 105–152.
External links
- Data Mining at DMOZ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
UpToDate Contents
全文を閲覧するには購読必要です。 To read the full text you will need to subscribe.
- 1. 臨床腫瘍学における遺伝子発現プロファイリング、プロテオミクス、およびマイクロ
RNAプロファイリングの概要 overview of gene expression profiling proteomics and microrna profiling in clinical oncology - 2. 上皮性卵巣癌、卵管癌、または原発性腹膜癌患者の付属器腫瘤の評価のための血清
バイオマーカー serum biomarkers for evaluation of an adnexal mass for epithelial carcinoma of the ovary fallopian tube or peritoneum - 3. 成人における高度な緊急気道マネージメント advanced emergency airway management in adults
- 4. 冠動脈バイパス術後の手術死亡率 operative mortality after coronary artery bypass graft surgery
- 5. 全身性硬化症(強皮症)の危険因子および考えられる原因 risk factors for and possible causes of systemic sclerosis scleroderma
English Journal
- Evaluation of chlorophyll-a retrieval algorithms based on MERIS bands for optically varying eutrophic inland lakes.
- Lyu H1, Li X2, Wang Y3, Jin Q3, Cao K4, Wang Q5, Li Y6.
- The Science of the total environment.Sci Total Environ.2015 Oct 15;530-531:373-82. doi: 10.1016/j.scitotenv.2015.05.115. Epub 2015 Jun 5.
- Fourteen field campaigns were conducted in five inland lakes during different seasons between 2006 and 2013, and a total of 398 water samples with varying optical characteristics were collected. The characteristics were analyzed based on remote sensing reflectance, and an automatic cluster two-step
- PMID 26057542
- Transcriptional profiles underpin microsatellite status and associated features in colon cancer.
- Hogan J1, DeJulius K2, Liu X3, Coffey JC4, Kalady MF5.
- Gene.Gene.2015 Oct 1;570(1):36-43. doi: 10.1016/j.gene.2015.02.057. Epub 2015 Feb 20.
- INTRODUCTION: While microsatellite instability is associated with prognosis and distinct clinical phenotypes in colon cancer, the basis for this remains incompletely defined. Novel bioinformatic techniques enable a detailed interrogation of the relationship between gene expression profiles and tumor
- PMID 25704535
- Egocentric Daily Activity Recognition via Multitask Clustering.
- Yan Y, Ricci E, Liu G, Sebe N.
- IEEE transactions on image processing : a publication of the IEEE Signal Processing Society.IEEE Trans Image Process.2015 Oct;24(10):2984-95. doi: 10.1109/TIP.2015.2438540.
- Recognizing human activities from videos is a fundamental research problem in computer vision. Recently, there has been a growing interest in analyzing human behavior from data collected with wearable cameras. First-person cameras continuously record several hours of their wearers' life. To cope wit
- PMID 26067371
Japanese Journal
- Fuzzy c-Means with Quadratic Penalty-Vector Regularization Using Kullback-Leibler Information for Uncertain Data
- Journal of advanced computational intelligence and intelligent informatics 19(5), 624-631, 2015-09
- NAID 40020618218
- 型を重視した通信ネットワークトポロジー設計手法 (インターネットアーキテクチャ)
- 電子情報通信学会技術研究報告 = IEICE technical report : 信学技報 115(192), 17-22, 2015-08-25
- NAID 40020588969
- Image compensation using wavelet transform for tilt servo control in holographic data storage system
- Jpn. J. Appl. Phys. 54(9S), 09MA05, 2015-08-20
- NAID 150000111263
Related Links
- The Microsoft Clustering algorithm first identifies relationships in a dataset and generates a series of clusters based on those relationships. A scatter plot is a useful way to visually represent how the algorithm groups data, as shown ...
- The Microsoft Clustering algorithm is a segmentation algorithm provided by Analysis Services. The algorithm uses iterative techniques to group cases in a dataset into clusters that contain similar characteristics. ... When you prepare ...
★リンクテーブル★
| 関連記事 | 「clustering」「algorithm」 |
「clustering」
- n.
「algorithm」